 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFog Robotics: A Summary, Challenges and Future Scope
Aug 14, 2019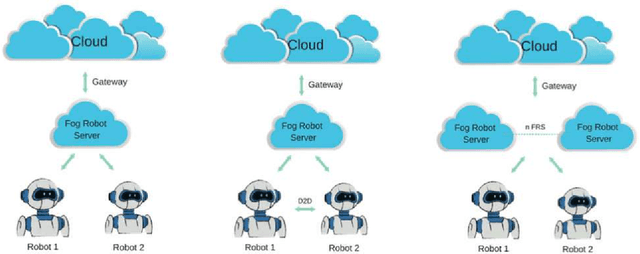
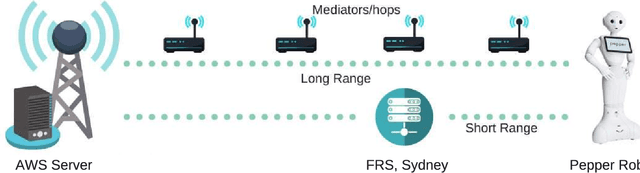
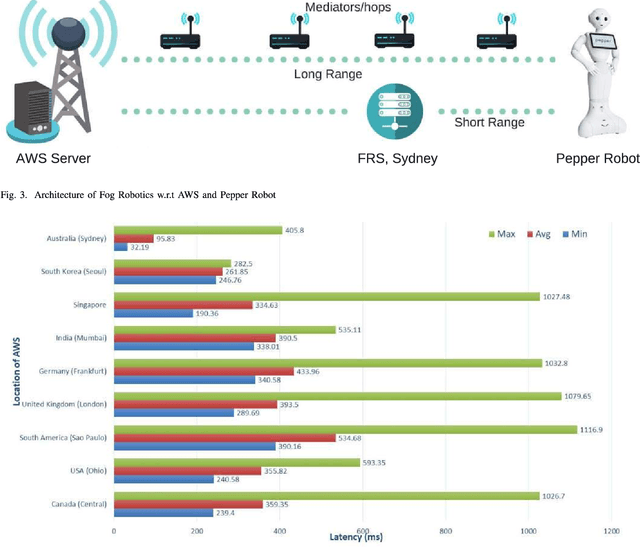
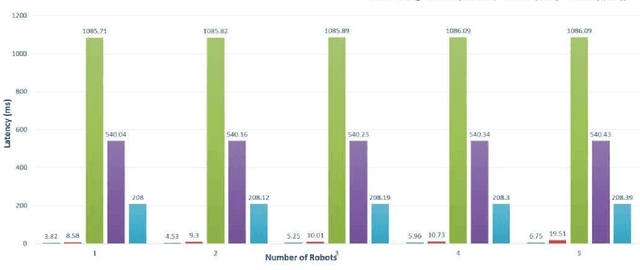
Human-robot interaction plays a crucial role to make robots closer to humans. Usually, robots are limited by their own capabilities. Therefore, they utilise Cloud Robotics to enhance their dexterity. Its ability includes the sharing of information such as maps, images and the processing power. This whole process involves distributing data which intend to rise enormously. New issues can arise such as bandwidth, network congestion at backhaul and fronthaul systems resulting in high latency. Thus, it can make an impact on seamless connectivity between the robots, users and the cloud. Also, a robot may not accomplish its goal successfully within a stipulated time. As a consequence, Cloud Robotics cannot be in a position to handle the traffic imposed by robots. On the contrary, impending Fog Robotics can act as a solution by solving major problems of Cloud Robotics. Therefore to check its feasibility, we discuss the need and architectures of Fog Robotics in this paper. To evaluate the architectures, we used a realistic scenario of Fog Robotics by comparing them with Cloud Robotics. Next, latency is chosen as the primary factor for validating the effectiveness of the system. Besides, we utilised real-time latency using Pepper robot, Fog robot server and the Cloud server. Experimental results show that Fog Robotics reduces latency significantly compared to Cloud Robotics. Moreover, advantages, challenges and future scope of the Fog Robotics system is further discussed.
Fog Robotics for Efficient, Fluent and Robust Human-Robot Interaction
Nov 14, 2018
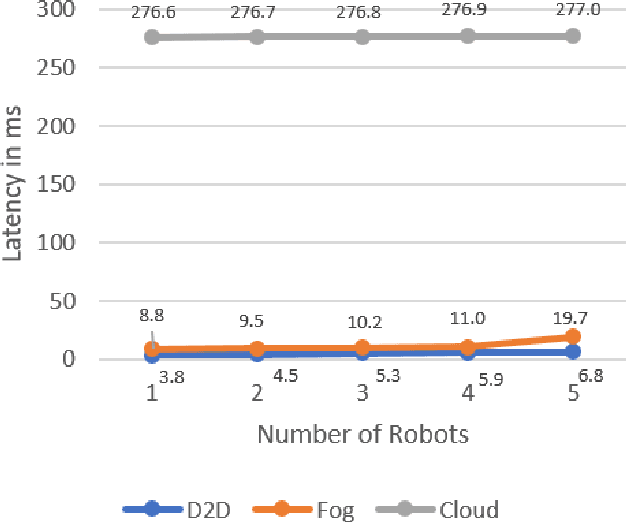

Active communication between robots and humans is essential for effective human-robot interaction. To accomplish this objective, Cloud Robotics (CR) was introduced to make robots enhance their capabilities. It enables robots to perform extensive computations in the cloud by sharing their outcomes. Outcomes include maps, images, processing power, data, activities, and other robot resources. But due to the colossal growth of data and traffic, CR suffers from serious latency issues. Therefore, it is unlikely to scale a large number of robots particularly in human-robot interaction scenarios, where responsiveness is paramount. Furthermore, other issues related to security such as privacy breaches and ransomware attacks can increase. To address these problems, in this paper, we have envisioned the next generation of social robotic architectures based on Fog Robotics (FR) that inherits the strengths of Fog Computing to augment the future social robotic systems. These new architectures can escalate the dexterity of robots by shoving the data closer to the robot. Additionally, they can ensure that human-robot interaction is more responsive by resolving the problems of CR. Moreover, experimental results are further discussed by considering a scenario of FR and latency as a primary factor comparing to CR models.
A Fully Automated System for Sizing Nasal PAP Masks Using Facial Photographs
Nov 09, 2018


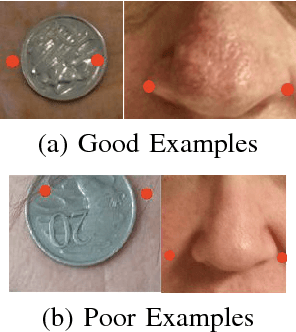
We present a fully automated system for sizing nasal Positive Airway Pressure (PAP) masks. The system is comprised of a mix of HOG object detectors as well as multiple convolutional neural network stages for facial landmark detection. The models were trained using samples from the publicly available PUT and MUCT datasets while transfer learning was also employed to improve the performance of the models on facial photographs of actual PAP mask users. The fully automated system demonstrated an overall accuracy of 64.71% in correctly selecting the appropriate mask size and 86.1% accuracy sizing within 1 mask size.
Semi-Automated Nasal PAP Mask Sizing using Facial Photographs
Sep 21, 2017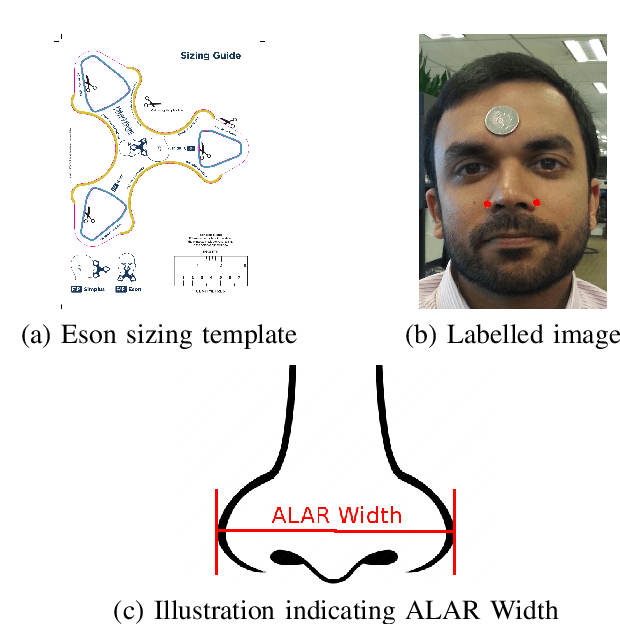
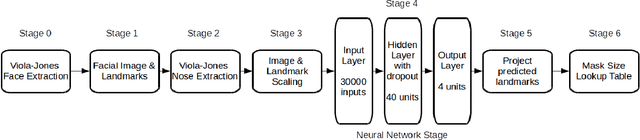
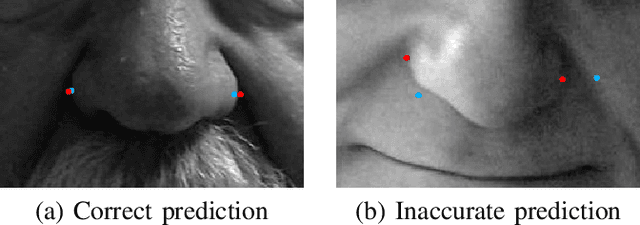
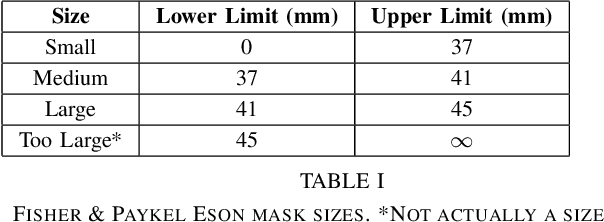
We present a semi-automated system for sizing nasal Positive Airway Pressure (PAP) masks based upon a neural network model that was trained with facial photographs of both PAP mask users and non-users. It demonstrated an accuracy of 72% in correctly sizing a mask and 96% accuracy sizing to within 1 mask size group. The semi-automated system performed comparably to sizing from manual measurements taken from the same images which produced 89% and 100% accuracy respectively.
The face-space duality hypothesis: a computational model
Sep 23, 2016
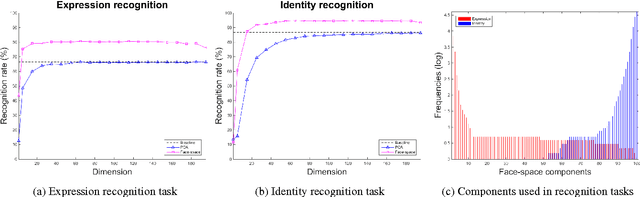
Valentine's face-space suggests that faces are represented in a psychological multidimensional space according to their perceived properties. However, the proposed framework was initially designed as an account of invariant facial features only, and explanations for dynamic features representation were neglected. In this paper we propose, develop and evaluate a computational model for a twofold structure of the face-space, able to unify both identity and expression representations in a single implemented model. To capture both invariant and dynamic facial features we introduce the face-space duality hypothesis and subsequently validate it through a mathematical presentation using a general approach to dimensionality reduction. Two experiments with real facial images show that the proposed face-space: (1) supports both identity and expression recognition, and (2) has a twofold structure anticipated by our formal argument.
Socially Impaired Robots: Human Social Disorders and Robots' Socio-Emotional Intelligence
Feb 15, 2016Social robots need intelligence in order to safely coexist and interact with humans. Robots without functional abilities in understanding others and unable to empathise might be a societal risk and they may lead to a society of socially impaired robots. In this work we provide a survey of three relevant human social disorders, namely autism, psychopathy and schizophrenia, as a means to gain a better understanding of social robots' future capability requirements. We provide evidence supporting the idea that social robots will require a combination of emotional intelligence and social intelligence, namely socio-emotional intelligence. We argue that a robot with a simple socio-emotional process requires a simulation-driven model of intelligence. Finally, we provide some critical guidelines for designing future socio-emotional robots.
Affective Facial Expression Processing via Simulation: A Probabilistic Model
Nov 03, 2014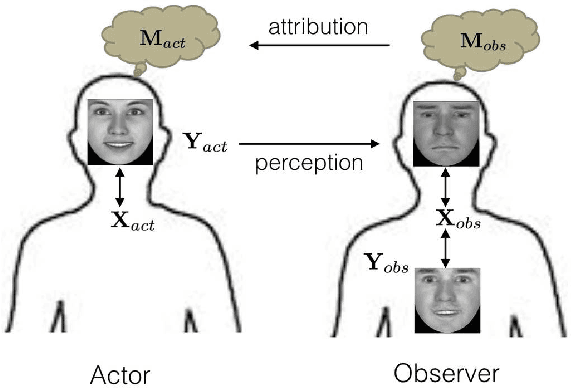
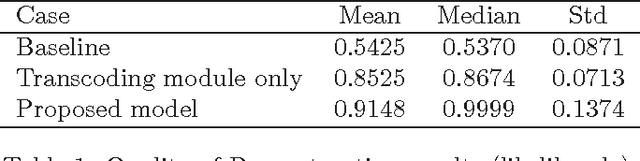
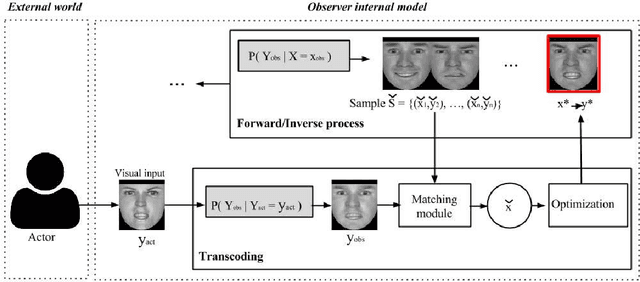

Understanding the mental state of other people is an important skill for intelligent agents and robots to operate within social environments. However, the mental processes involved in `mind-reading' are complex. One explanation of such processes is Simulation Theory - it is supported by a large body of neuropsychological research. Yet, determining the best computational model or theory to use in simulation-style emotion detection, is far from being understood. In this work, we use Simulation Theory and neuroscience findings on Mirror-Neuron Systems as the basis for a novel computational model, as a way to handle affective facial expressions. The model is based on a probabilistic mapping of observations from multiple identities onto a single fixed identity (`internal transcoding of external stimuli'), and then onto a latent space (`phenomenological response'). Together with the proposed architecture we present some promising preliminary results