 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighting Is Worth the Wait: Bayesian Optimization with Importance Sampling
Paper and Code
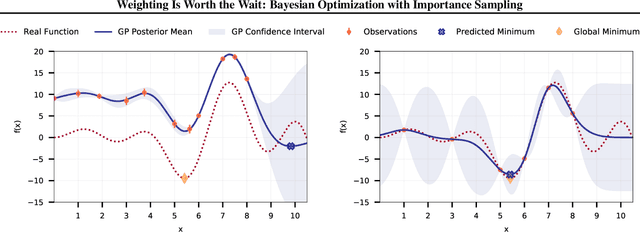
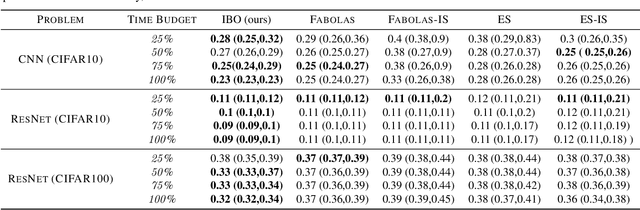
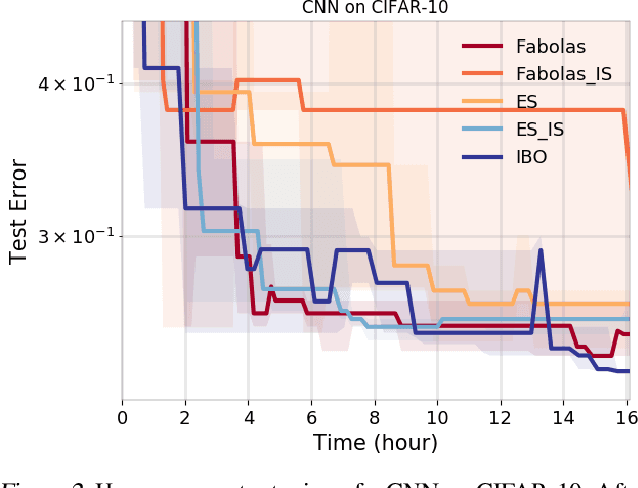
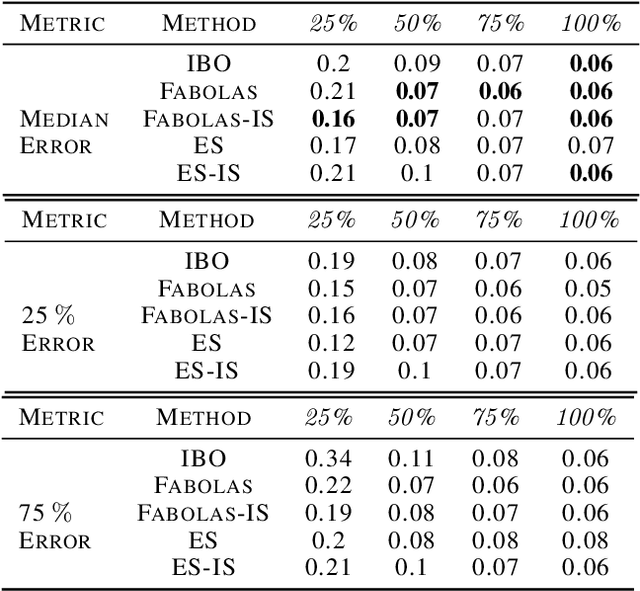
Many contemporary machine learning models require extensive tuning of hyperparameters to perform well. A variety of methods, such as Bayesian optimization, have been developed to automate and expedite this process. However, tuning remains extremely costly as it typically requires repeatedly fully training models. We propose to accelerate the Bayesian optimization approach to hyperparameter tuning for neural networks by taking into account the relative amount of information contributed by each training example. To do so, we leverage importance sampling (IS); this significantly increases the quality of the black-box function evaluations, but also their runtime, and so must be done carefully. Casting hyperparameter search as a multi-task Bayesian optimization problem over both hyperparameters and importance sampling design achieves the best of both worlds: by learning a parameterization of IS that trades-off evaluation complexity and quality, we improve upon Bayesian optimization state-of-the-art runtime and final validation error across a variety of datasets and complex neural architectures.