 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo Wide, Then Narrow: Efficient Training of Deep Thin Networks
Paper and Code
Jul 01, 2020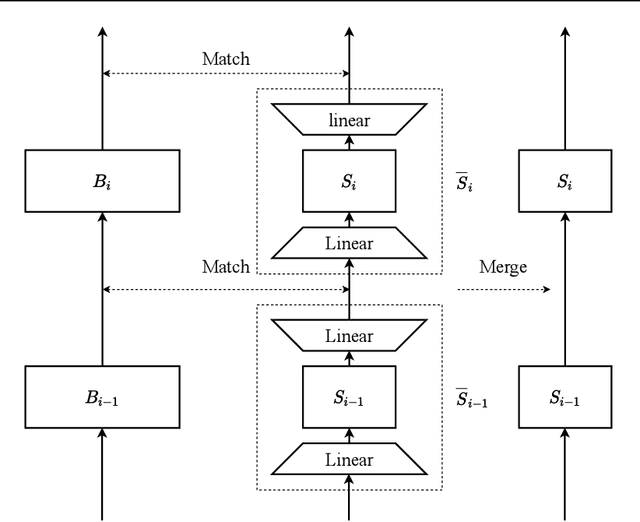
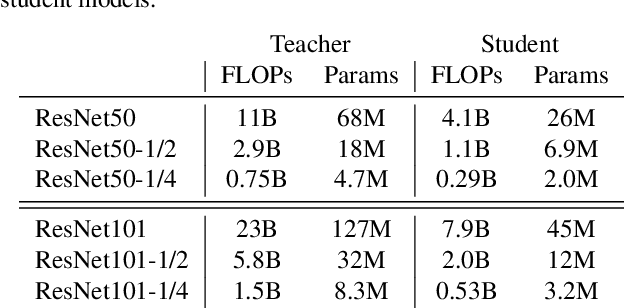
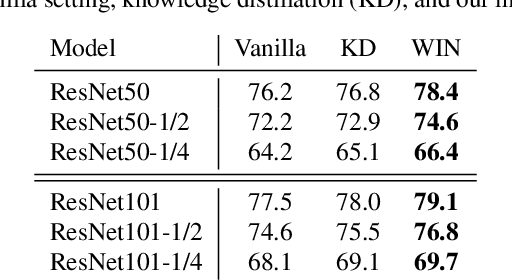
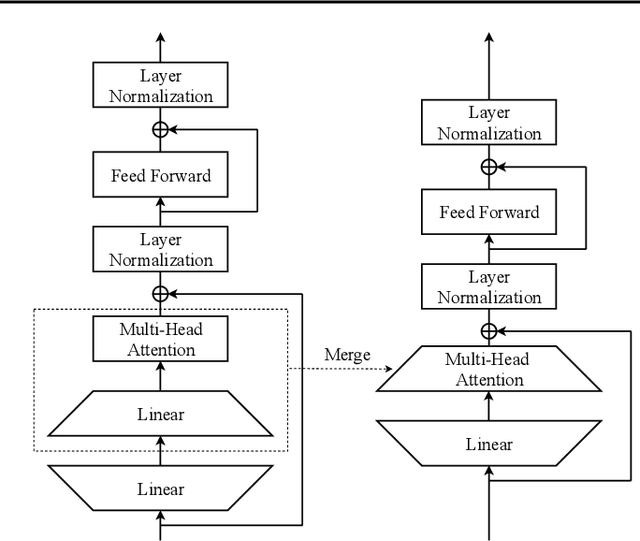
For deploying a deep learning model into production, it needs to be both accurate and compact to meet the latency and memory constraints. This usually results in a network that is deep (to ensure performance) and yet thin (to improve computational efficiency). In this paper, we propose an efficient method to train a deep thin network with a theoretic guarantee. Our method is motivated by model compression. It consists of three stages. In the first stage, we sufficiently widen the deep thin network and train it until convergence. In the second stage, we use this well-trained deep wide network to warm up (or initialize) the original deep thin network. This is achieved by letting the thin network imitate the immediate outputs of the wide network from layer to layer. In the last stage, we further fine tune this well initialized deep thin network. The theoretical guarantee is established by using mean field analysis, which shows the advantage of layerwise imitation over traditional training deep thin networks from scratch by backpropagation. We also conduct large-scale empirical experiments to validate our approach. By training with our method, ResNet50 can outperform ResNet101, and BERT_BASE can be comparable with BERT_LARGE, where both the latter models are trained via the standard training procedures as in the literature.