 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD: Fully-Specialized Detector via Neural Architecture Search
Jun 12, 2023



Most generic object detectors are mainly built for standard object detection tasks such as COCO and PASCAL VOC. They might not work well and/or efficiently on tasks of other domains consisting of images that are visually different from standard datasets. To this end, many advances have been focused on adapting a general-purposed object detector with limited domain-specific designs. However, designing a successful task-specific detector requires extraneous manual experiments and parameter tuning through trial and error. In this paper, we first propose and examine a fully-automatic pipeline to design a fully-specialized detector (FSD) which mainly incorporates a neural-architectural-searched model by exploring ideal network structures over the backbone and task-specific head. On the DeepLesion dataset, extensive results show that FSD can achieve 3.1 mAP gain while using approximately 40% fewer parameters on binary lesion detection task and improved the mAP by around 10% on multi-type lesion detection task via our region-aware graph modeling compared with existing general-purposed medical lesion detection networks.
Towards Improving Generalization of Deep Networks via Consistent Normalization
Aug 31, 2019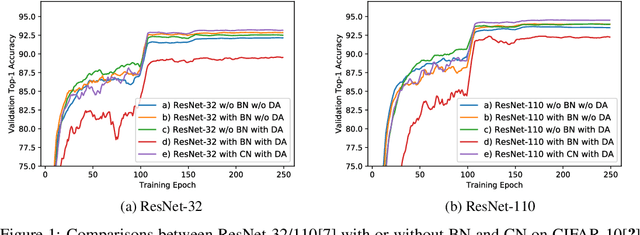
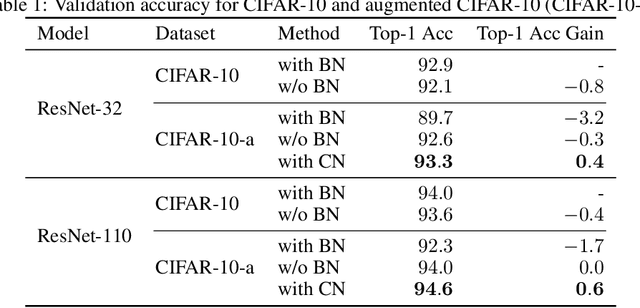

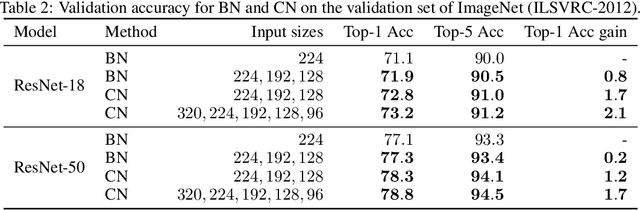
Batch Normalization (BN) was shown to accelerate training and improve generalization of Convolutional Neural Networks (ConvNets), which typically use the Conv-BN couple as building block. However, this work shows a common phenomenon that the Conv-BN module does not necessarily outperform the networks trained without using BN, especially when data augmentation is presented in training. We find that this phenomenon occurs because there is inconsistency between the distribution of the augmented data and that of the normalized representation. To address this issue, we propose Consistent Normalization (CN) that not only retains the advantages of the existing normalization methods, but also achieves state-of-the-art performance on various tasks including image classification, segmentation, and machine translation. The code will be released to facilitate reproducibility.
SSN: Learning Sparse Switchable Normalization via SparsestMax
Mar 09, 2019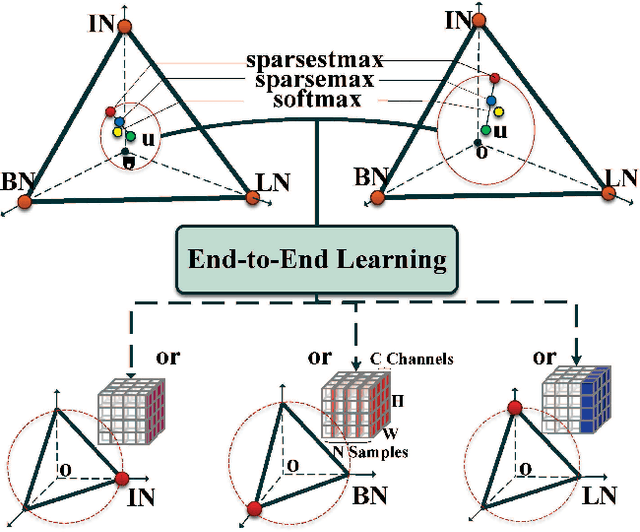
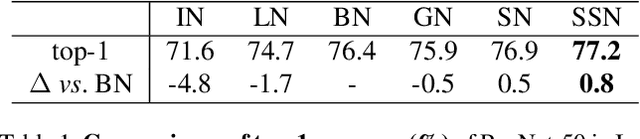
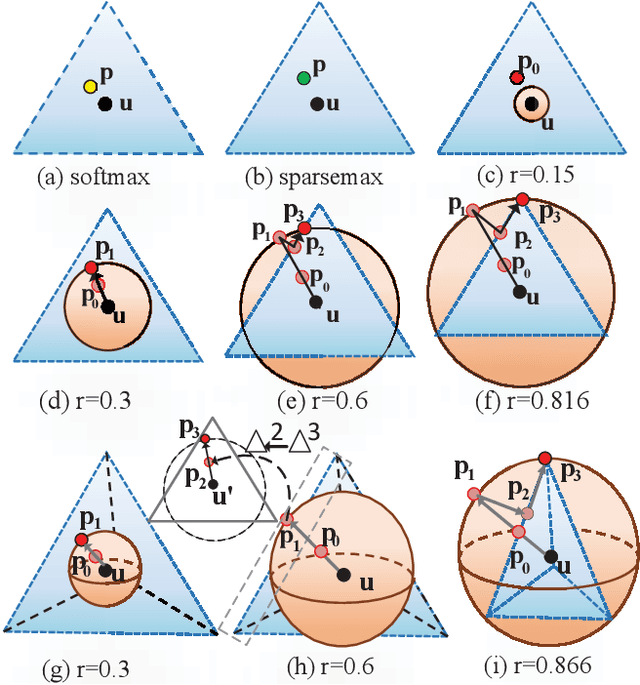
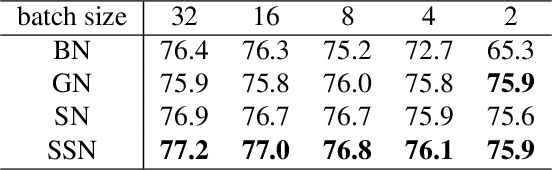
Normalization methods improve both optimization and generalization of ConvNets. To further boost performance, the recently-proposed switchable normalization (SN) provides a new perspective for deep learning: it learns to select different normalizers for different convolution layers of a ConvNet. However, SN uses softmax function to learn importance ratios to combine normalizers, leading to redundant computations compared to a single normalizer. This work addresses this issue by presenting Sparse Switchable Normalization (SSN) where the importance ratios are constrained to be sparse. Unlike $\ell_1$ and $\ell_0$ constraints that impose difficulties in optimization, we turn this constrained optimization problem into feed-forward computation by proposing SparsestMax, which is a sparse version of softmax. SSN has several appealing properties. (1) It inherits all benefits from SN such as applicability in various tasks and robustness to a wide range of batch sizes. (2) It is guaranteed to select only one normalizer for each normalization layer, avoiding redundant computations. (3) SSN can be transferred to various tasks in an end-to-end manner. Extensive experiments show that SSN outperforms its counterparts on various challenging benchmarks such as ImageNet, Cityscapes, ADE20K, and Kinetics.
A Main/Subsidiary Network Framework for Simplifying Binary Neural Network
Dec 11, 2018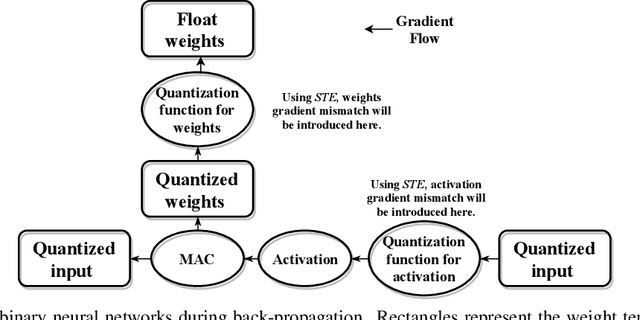
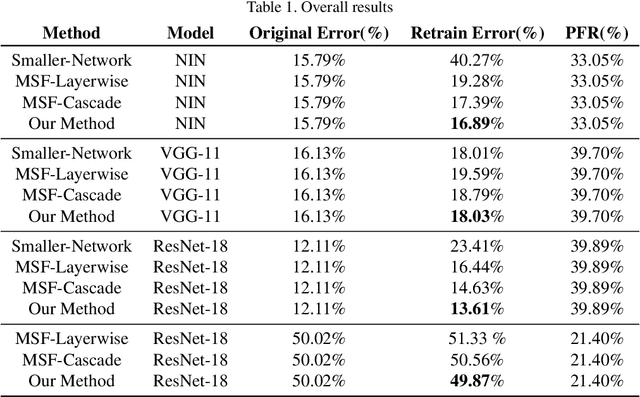
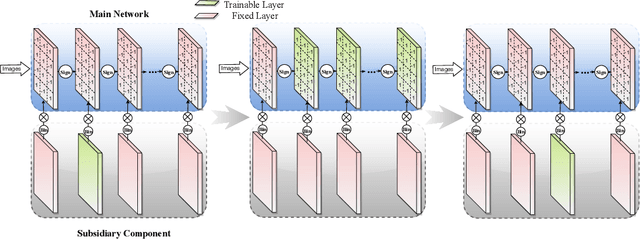

To reduce memory footprint and run-time latency, techniques such as neural network pruning and binarization have been explored separately. However, it is unclear how to combine the best of the two worlds to get extremely small and efficient models. In this paper, we, for the first time, define the filter-level pruning problem for binary neural networks, which cannot be solved by simply migrating existing structural pruning methods for full-precision models. A novel learning-based approach is proposed to prune filters in our main/subsidiary network framework, where the main network is responsible for learning representative features to optimize the prediction performance, and the subsidiary component works as a filter selector on the main network. To avoid gradient mismatch when training the subsidiary component, we propose a layer-wise and bottom-up scheme. We also provide the theoretical and experimental comparison between our learning-based and greedy rule-based methods. Finally, we empirically demonstrate the effectiveness of our approach applied on several binary models, including binarized NIN, VGG-11, and ResNet-18, on various image classification datasets.