 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud
Sep 19, 2022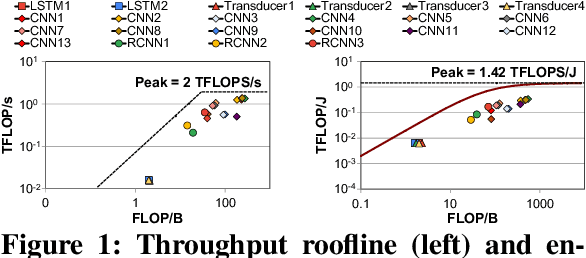
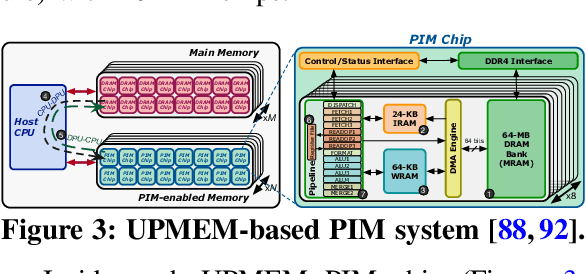

Neural networks (NNs) are growing in importance and complexity. A neural network's performance (and energy efficiency) can be bound either by computation or memory resources. The processing-in-memory (PIM) paradigm, where computation is placed near or within memory arrays, is a viable solution to accelerate memory-bound NNs. However, PIM architectures vary in form, where different PIM approaches lead to different trade-offs. Our goal is to analyze, discuss, and contrast DRAM-based PIM architectures for NN performance and energy efficiency. To do so, we analyze three state-of-the-art PIM architectures: (1) UPMEM, which integrates processors and DRAM arrays into a single 2D chip; (2) Mensa, a 3D-stack-based PIM architecture tailored for edge devices; and (3) SIMDRAM, which uses the analog principles of DRAM to execute bit-serial operations. Our analysis reveals that PIM greatly benefits memory-bound NNs: (1) UPMEM provides 23x the performance of a high-end GPU when the GPU requires memory oversubscription for a general matrix-vector multiplication kernel; (2) Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Google Edge TPU for 24 Google edge NN models; and (3) SIMDRAM outperforms a CPU/GPU by 16.7x/1.4x for three binary NNs. We conclude that the ideal PIM architecture for NN models depends on a model's distinct attributes, due to the inherent architectural design choices.
Heterogeneous Data-Centric Architectures for Modern Data-Intensive Applications: Case Studies in Machine Learning and Databases
May 29, 2022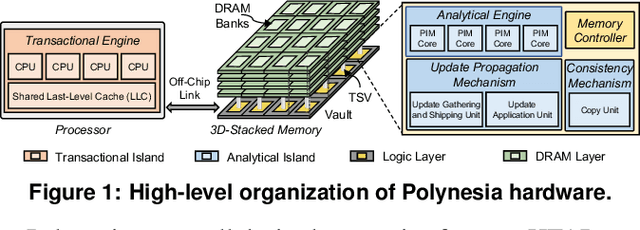
Today's computing systems require moving data back-and-forth between computing resources (e.g., CPUs, GPUs, accelerators) and off-chip main memory so that computation can take place on the data. Unfortunately, this data movement is a major bottleneck for system performance and energy consumption. One promising execution paradigm that alleviates the data movement bottleneck in modern and emerging applications is processing-in-memory (PIM), where the cost of data movement to/from main memory is reduced by placing computation capabilities close to memory. Naively employing PIM to accelerate data-intensive workloads can lead to sub-optimal performance due to the many design constraints PIM substrates impose. Therefore, many recent works co-design specialized PIM accelerators and algorithms to improve performance and reduce the energy consumption of (i) applications from various application domains; and (ii) various computing environments, including cloud systems, mobile systems, and edge devices. We showcase the benefits of co-designing algorithms and hardware in a way that efficiently takes advantage of the PIM paradigm for two modern data-intensive applications: (1) machine learning inference models for edge devices and (2) hybrid transactional/analytical processing databases for cloud systems. We follow a two-step approach in our system design. In the first step, we extensively analyze the computation and memory access patterns of each application to gain insights into its hardware/software requirements and major sources of performance and energy bottlenecks in processor-centric systems. In the second step, we leverage the insights from the first step to co-design algorithms and hardware accelerators to enable high-performance and energy-efficient data-centric architectures for each application.
Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Sep 29, 2021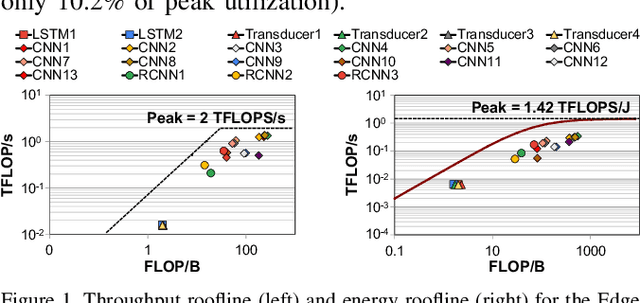
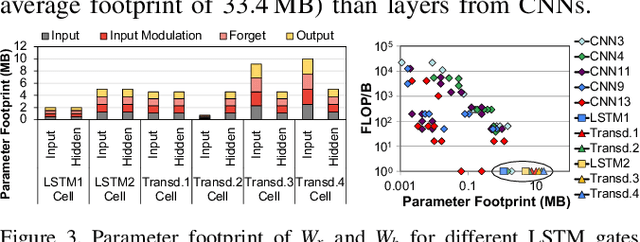
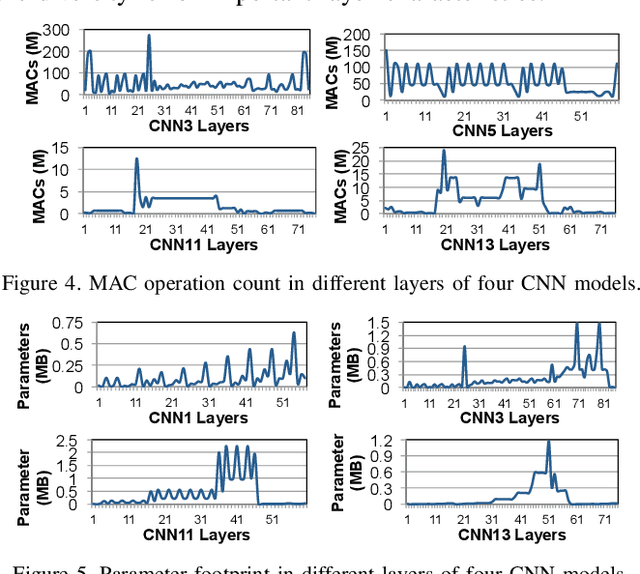
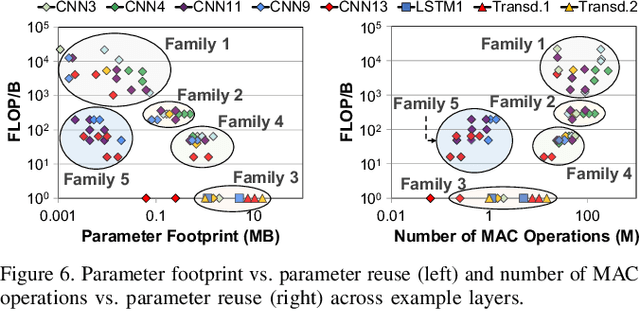
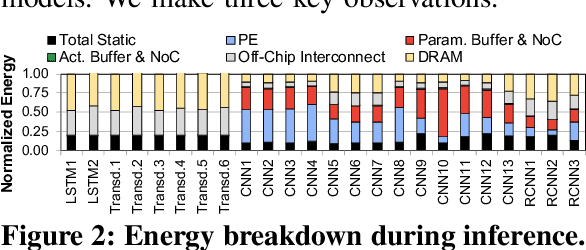
Emerging edge computing platforms often contain machine learning (ML) accelerators that can accelerate inference for a wide range of neural network (NN) models. These models are designed to fit within the limited area and energy constraints of the edge computing platforms, each targeting various applications (e.g., face detection, speech recognition, translation, image captioning, video analytics). To understand how edge ML accelerators perform, we characterize the performance of a commercial Google Edge TPU, using 24 Google edge NN models (which span a wide range of NN model types) and analyzing each NN layer within each model. We find that the Edge TPU suffers from three major shortcomings: (1) it operates significantly below peak computational throughput, (2) it operates significantly below its theoretical energy efficiency, and (3) its memory system is a large energy and performance bottleneck. Our characterization reveals that the one-size-fits-all, monolithic design of the Edge TPU ignores the high degree of heterogeneity both across different NN models and across different NN layers within the same NN model, leading to the shortcomings we observe. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous edge ML accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of NN models and layers. During NN inference, for each NN layer, Mensa decides which accelerator to schedule the layer on, taking into account both the optimality of each accelerator for the layer and layer-to-layer communication costs. Averaged across all 24 Google edge NN models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss~v2, a state-of-the-art accelerator.
Mitigating Edge Machine Learning Inference Bottlenecks: An Empirical Study on Accelerating Google Edge Models
Mar 01, 2021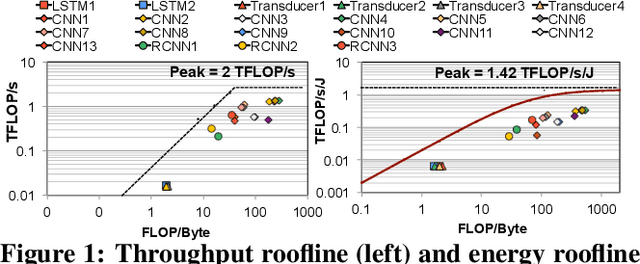
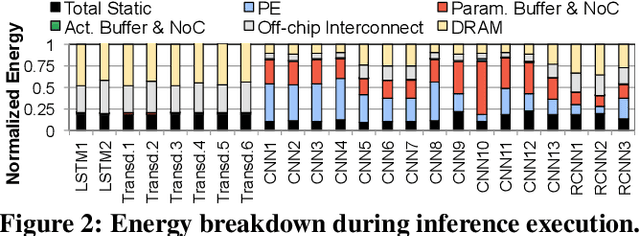
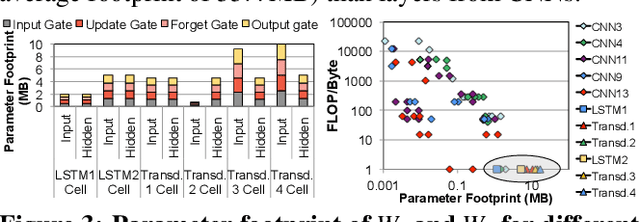
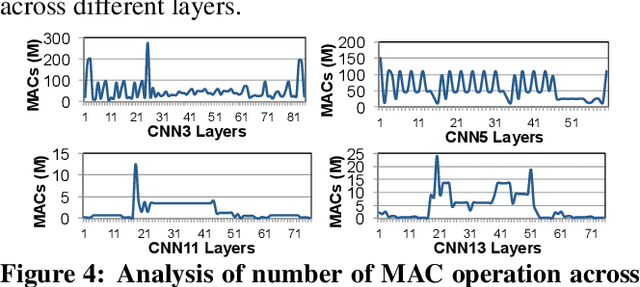
As the need for edge computing grows, many modern consumer devices now contain edge machine learning (ML) accelerators that can compute a wide range of neural network (NN) models while still fitting within tight resource constraints. We analyze a commercial Edge TPU using 24 Google edge NN models (including CNNs, LSTMs, transducers, and RCNNs), and find that the accelerator suffers from three shortcomings, in terms of computational throughput, energy efficiency, and memory access handling. We comprehensively study the characteristics of each NN layer in all of the Google edge models, and find that these shortcomings arise from the one-size-fits-all approach of the accelerator, as there is a high amount of heterogeneity in key layer characteristics both across different models and across different layers in the same model. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous ML edge accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of models. At runtime, Mensa schedules each layer to run on the best-suited accelerator, accounting for both efficiency and inter-layer dependencies. As we analyze the Google edge NN models, we discover that all of the layers naturally group into a small number of clusters, which allows us to design an efficient implementation of Mensa for these models with only three specialized accelerators. Averaged across all 24 Google edge models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss v2, a state-of-the-art accelerator.