 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Data-Centric Architectures for Modern Data-Intensive Applications: Case Studies in Machine Learning and Databases
Paper and Code
May 29, 2022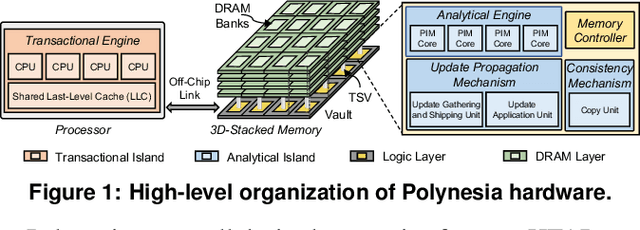
Today's computing systems require moving data back-and-forth between computing resources (e.g., CPUs, GPUs, accelerators) and off-chip main memory so that computation can take place on the data. Unfortunately, this data movement is a major bottleneck for system performance and energy consumption. One promising execution paradigm that alleviates the data movement bottleneck in modern and emerging applications is processing-in-memory (PIM), where the cost of data movement to/from main memory is reduced by placing computation capabilities close to memory. Naively employing PIM to accelerate data-intensive workloads can lead to sub-optimal performance due to the many design constraints PIM substrates impose. Therefore, many recent works co-design specialized PIM accelerators and algorithms to improve performance and reduce the energy consumption of (i) applications from various application domains; and (ii) various computing environments, including cloud systems, mobile systems, and edge devices. We showcase the benefits of co-designing algorithms and hardware in a way that efficiently takes advantage of the PIM paradigm for two modern data-intensive applications: (1) machine learning inference models for edge devices and (2) hybrid transactional/analytical processing databases for cloud systems. We follow a two-step approach in our system design. In the first step, we extensively analyze the computation and memory access patterns of each application to gain insights into its hardware/software requirements and major sources of performance and energy bottlenecks in processor-centric systems. In the second step, we leverage the insights from the first step to co-design algorithms and hardware accelerators to enable high-performance and energy-efficient data-centric architectures for each application.