 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud
Paper and Code
Sep 19, 2022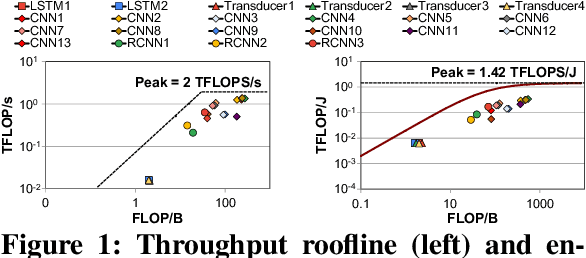
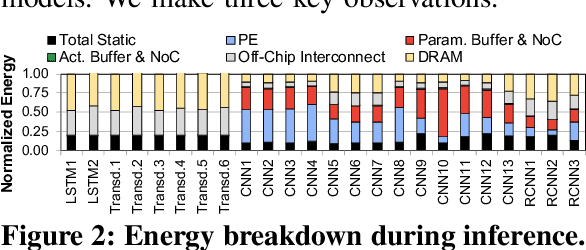
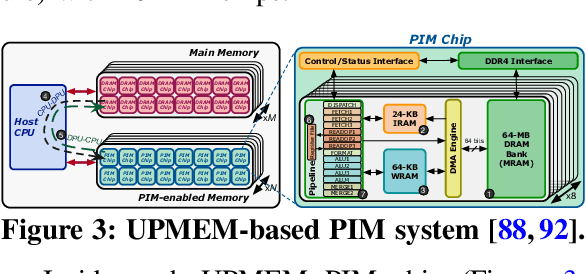

Neural networks (NNs) are growing in importance and complexity. A neural network's performance (and energy efficiency) can be bound either by computation or memory resources. The processing-in-memory (PIM) paradigm, where computation is placed near or within memory arrays, is a viable solution to accelerate memory-bound NNs. However, PIM architectures vary in form, where different PIM approaches lead to different trade-offs. Our goal is to analyze, discuss, and contrast DRAM-based PIM architectures for NN performance and energy efficiency. To do so, we analyze three state-of-the-art PIM architectures: (1) UPMEM, which integrates processors and DRAM arrays into a single 2D chip; (2) Mensa, a 3D-stack-based PIM architecture tailored for edge devices; and (3) SIMDRAM, which uses the analog principles of DRAM to execute bit-serial operations. Our analysis reveals that PIM greatly benefits memory-bound NNs: (1) UPMEM provides 23x the performance of a high-end GPU when the GPU requires memory oversubscription for a general matrix-vector multiplication kernel; (2) Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Google Edge TPU for 24 Google edge NN models; and (3) SIMDRAM outperforms a CPU/GPU by 16.7x/1.4x for three binary NNs. We conclude that the ideal PIM architecture for NN models depends on a model's distinct attributes, due to the inherent architectural design choices.