 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOL: Meeting Diverse Distribution Shifts with Prior Physics for Tropical Cyclone Multi-Task Estimation
Nov 13, 2025



Tropical Cyclone (TC) estimation aims to accurately estimate various TC attributes in real time. However, distribution shifts arising from the complex and dynamic nature of TC environmental fields, such as varying geographical conditions and seasonal changes, present significant challenges to reliable estimation. Most existing methods rely on multi-modal fusion for feature extraction but overlook the intrinsic distribution of feature representations, leading to poor generalization under out-of-distribution (OOD) scenarios. To address this, we propose an effective Identity Distribution-Oriented Physical Invariant Learning framework (IDOL), which imposes identity-oriented constraints to regulate the feature space under the guidance of prior physical knowledge, thereby dealing distribution variability with physical invariance. Specifically, the proposed IDOL employs the wind field model and dark correlation knowledge of TC to model task-shared and task-specific identity tokens. These tokens capture task dependencies and intrinsic physical invariances of TC, enabling robust estimation of TC wind speed, pressure, inner-core, and outer-core size under distribution shifts. Extensive experiments conducted on multiple datasets and tasks demonstrate the outperformance of the proposed IDOL, verifying that imposing identity-oriented constraints based on prior physical knowledge can effectively mitigates diverse distribution shifts in TC estimation.Code is available at https://github.com/Zjut-MultimediaPlus/IDOL.
NeighborRetr: Balancing Hub Centrality in Cross-Modal Retrieval
Mar 13, 2025Cross-modal retrieval aims to bridge the semantic gap between different modalities, such as visual and textual data, enabling accurate retrieval across them. Despite significant advancements with models like CLIP that align cross-modal representations, a persistent challenge remains: the hubness problem, where a small subset of samples (hubs) dominate as nearest neighbors, leading to biased representations and degraded retrieval accuracy. Existing methods often mitigate hubness through post-hoc normalization techniques, relying on prior data distributions that may not be practical in real-world scenarios. In this paper, we directly mitigate hubness during training and introduce NeighborRetr, a novel method that effectively balances the learning of hubs and adaptively adjusts the relations of various kinds of neighbors. Our approach not only mitigates the hubness problem but also enhances retrieval performance, achieving state-of-the-art results on multiple cross-modal retrieval benchmarks. Furthermore, NeighborRetr demonstrates robust generalization to new domains with substantial distribution shifts, highlighting its effectiveness in real-world applications. We make our code publicly available at: https://github.com/zzezze/NeighborRetr .
TCP-Diffusion: A Multi-modal Diffusion Model for Global Tropical Cyclone Precipitation Forecasting with Change Awareness
Oct 17, 2024Precipitation from tropical cyclones (TCs) can cause disasters such as flooding, mudslides, and landslides. Predicting such precipitation in advance is crucial, giving people time to prepare and defend against these precipitation-induced disasters. Developing deep learning (DL) rainfall prediction methods offers a new way to predict potential disasters. However, one problem is that most existing methods suffer from cumulative errors and lack physical consistency. Second, these methods overlook the importance of meteorological factors in TC rainfall and their integration with the numerical weather prediction (NWP) model. Therefore, we propose Tropical Cyclone Precipitation Diffusion (TCP-Diffusion), a multi-modal model for global tropical cyclone precipitation forecasting. It forecasts TC rainfall around the TC center for the next 12 hours at 3 hourly resolution based on past rainfall observations and multi-modal environmental variables. Adjacent residual prediction (ARP) changes the training target from the absolute rainfall value to the rainfall trend and gives our model the ability of rainfall change awareness, reducing cumulative errors and ensuring physical consistency. Considering the influence of TC-related meteorological factors and the useful information from NWP model forecasts, we propose a multi-model framework with specialized encoders to extract richer information from environmental variables and results provided by NWP models. The results of extensive experiments show that our method outperforms other DL methods and the NWP method from the European Centre for Medium-Range Weather Forecasts (ECMWF).
Little Strokes Fell Great Oaks: Boosting the Hierarchical Features for Multi-exposure Image Fusion
Apr 10, 2024



In recent years, deep learning networks have made remarkable strides in the domain of multi-exposure image fusion. Nonetheless, prevailing approaches often involve directly feeding over-exposed and under-exposed images into the network, which leads to the under-utilization of inherent information present in the source images. Additionally, unsupervised techniques predominantly employ rudimentary weighted summation for color channel processing, culminating in an overall desaturated final image tone. To partially mitigate these issues, this study proposes a gamma correction module specifically designed to fully leverage latent information embedded within source images. Furthermore, a modified transformer block, embracing with self-attention mechanisms, is introduced to optimize the fusion process. Ultimately, a novel color enhancement algorithm is presented to augment image saturation while preserving intricate details. The source code is available at https://github.com/ZhiyingDu/BHFMEF.
A Generalized Physical-knowledge-guided Dynamic Model for Underwater Image Enhancement
Aug 10, 2023Underwater images often suffer from color distortion and low contrast resulting in various image types, due to the scattering and absorption of light by water. While it is difficult to obtain high-quality paired training samples with a generalized model. To tackle these challenges, we design a Generalized Underwater image enhancement method via a Physical-knowledge-guided Dynamic Model (short for GUPDM), consisting of three parts: Atmosphere-based Dynamic Structure (ADS), Transmission-guided Dynamic Structure (TDS), and Prior-based Multi-scale Structure (PMS). In particular, to cover complex underwater scenes, this study changes the global atmosphere light and the transmission to simulate various underwater image types (e.g., the underwater image color ranging from yellow to blue) through the formation model. We then design ADS and TDS that use dynamic convolutions to adaptively extract prior information from underwater images and generate parameters for PMS. These two modules enable the network to select appropriate parameters for various water types adaptively. Besides, the multi-scale feature extraction module in PMS uses convolution blocks with different kernel sizes and obtains weights for each feature map via channel attention block and fuses them to boost the receptive field of the network. The source code will be available at \href{https://github.com/shiningZZ/GUPDM}{https://github.com/shiningZZ/GUPDM}.
Towards General and Fast Video Derain via Knowledge Distillation
Aug 10, 2023



As a common natural weather condition, rain can obscure video frames and thus affect the performance of the visual system, so video derain receives a lot of attention. In natural environments, rain has a wide variety of streak types, which increases the difficulty of the rain removal task. In this paper, we propose a Rain Review-based General video derain Network via knowledge distillation (named RRGNet) that handles different rain streak types with one pre-training weight. Specifically, we design a frame grouping-based encoder-decoder network that makes full use of the temporal information of the video. Further, we use the old task model to guide the current model in learning new rain streak types while avoiding forgetting. To consolidate the network's ability to derain, we design a rain review module to play back data from old tasks for the current model. The experimental results show that our developed general method achieves the best results in terms of running speed and derain effect.
Transmission and Color-guided Network for Underwater Image Enhancement
Aug 09, 2023In recent years, with the continuous development of the marine industry, underwater image enhancement has attracted plenty of attention. Unfortunately, the propagation of light in water will be absorbed by water bodies and scattered by suspended particles, resulting in color deviation and low contrast. To solve these two problems, we propose an Adaptive Transmission and Dynamic Color guided network (named ATDCnet) for underwater image enhancement. In particular, to exploit the knowledge of physics, we design an Adaptive Transmission-directed Module (ATM) to better guide the network. To deal with the color deviation problem, we design a Dynamic Color-guided Module (DCM) to post-process the enhanced image color. Further, we design an Encoder-Decoder-based Compensation (EDC) structure with attention and a multi-stage feature fusion mechanism to perform color restoration and contrast enhancement simultaneously. Extensive experiments demonstrate the state-of-the-art performance of the ATDCnet on multiple benchmark datasets.
Histogram-guided Video Colorization Structure with Spatial-Temporal Connection
Aug 09, 2023Video colorization, aiming at obtaining colorful and plausible results from grayish frames, has aroused a lot of interest recently. Nevertheless, how to maintain temporal consistency while keeping the quality of colorized results remains challenging. To tackle the above problems, we present a Histogram-guided Video Colorization with Spatial-Temporal connection structure (named ST-HVC). To fully exploit the chroma and motion information, the joint flow and histogram module is tailored to integrate the histogram and flow features. To manage the blurred and artifact, we design a combination scheme attending to temporal detail and flow feature combination. We further recombine the histogram, flow and sharpness features via a U-shape network. Extensive comparisons are conducted with several state-of-the-art image and video-based methods, demonstrating that the developed method achieves excellent performance both quantitatively and qualitatively in two video datasets.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Triple-level Model Inferred Collaborative Network Architecture for Video Deraining
Nov 08, 2021
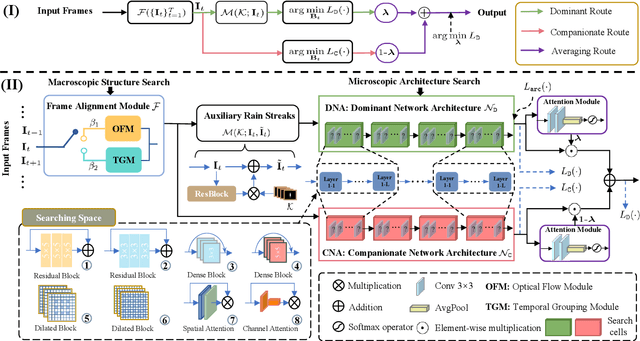
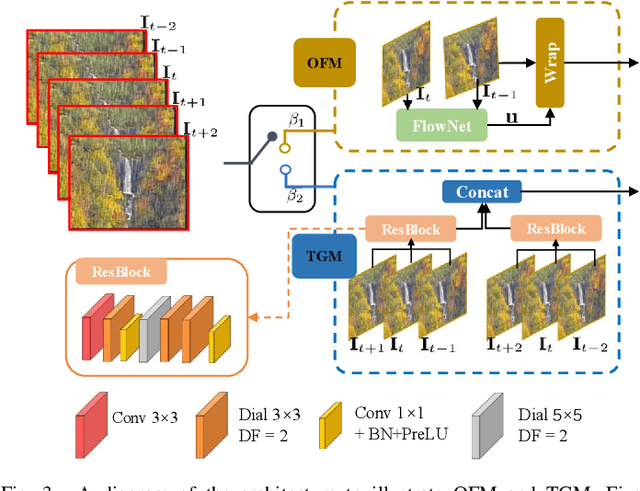
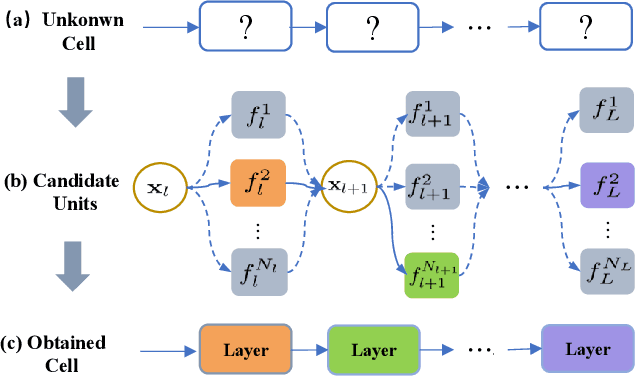
Video deraining is an important issue for outdoor vision systems and has been investigated extensively. However, designing optimal architectures by the aggregating model formation and data distribution is a challenging task for video deraining. In this paper, we develop a model-guided triple-level optimization framework to deduce network architecture with cooperating optimization and auto-searching mechanism, named Triple-level Model Inferred Cooperating Searching (TMICS), for dealing with various video rain circumstances. In particular, to mitigate the problem that existing methods cannot cover various rain streaks distribution, we first design a hyper-parameter optimization model about task variable and hyper-parameter. Based on the proposed optimization model, we design a collaborative structure for video deraining. This structure includes Dominant Network Architecture (DNA) and Companionate Network Architecture (CNA) that is cooperated by introducing an Attention-based Averaging Scheme (AAS). To better explore inter-frame information from videos, we introduce a macroscopic structure searching scheme that searches from Optical Flow Module (OFM) and Temporal Grouping Module (TGM) to help restore latent frame. In addition, we apply the differentiable neural architecture searching from a compact candidate set of task-specific operations to discover desirable rain streaks removal architectures automatically. Extensive experiments on various datasets demonstrate that our model shows significant improvements in fidelity and temporal consistency over the state-of-the-art works. Source code is available at https://github.com/vis-opt-group/TMICS.