 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speckle Holography Redefines Label-free Nanoparticle Phenotyping
May 03, 2026Nanoparticle metrology has long been constrained by the assumption that, in mixed and unprocessed fluids, particle size, morphology, composition, and species-specific abundance cannot be resolved simultaneously from a single label-free measurement. Here, we revisit this long-standing limitation by showing that complex forward speckle-holographic fields define an information-rich optical space for multidimensional particle signatures. We report deep speckle holography, a physics-informed generative framework that profiles particle identity, size, morphology, and species-resolved abundance from a single non-contact optical measurement. Across purified suspensions, mixed particle populations, environmental waters, human urine, and other unprocessed native fluids, the method enables direct nanoparticle inference without purification, labeling, or destructive preprocessing, delivering concurrent multidimensional readouts in 0.9 s over a dynamic range spanning 10 orders of magnitude. Deep speckle holography establishes a route toward direct label-free nanoparticle phenotyping in real-world fluids, moving nanoscale measurement beyond isolated-particle characterization toward multidimensional inference in complex mixtures, and expanding the scope of questions nanoscale measurement can address, from real-time tracking of nanoparticle transformations in living and environmental systems to non-invasive quality control of nanomedicine formulations, and beyond.
Rapid tracking through strongly scattering media with physics-informed neuromorphic speckle analysis
Apr 28, 2026This work addresses the critical problem of tracking fast-moving objects through strongly scattering media in a low-light environment. Different from existing approaches that use frame-based cameras with fixed exposure times, which trade off signal-to-noise ratio for temporal resolution, we introduce computational neuromorphic tracking (CNT), a physics-informed framework that combines asynchronous event sensing with task-driven speckle analysis for robust motion estimation. We formulate the neuromorphic speckle aggregation as a spatiotemporal speckle representation, jointly optimizing the temporal and spatial parameters to maximize tracking stability under extreme conditions. Extensive experiments demonstrate that our method enables robust motion tracking of 10x faster motion and under 10x dimmer illumination compared to conventional systems. These improvements significantly broaden the operational regime for tracking through scattering media, providing an efficient and scalable solution for demanding scenarios involving rapid motion and low-light conditions.
SA-GNAS: Seed Architecture Expansion for Efficient Large-scale Graph Neural Architecture Search
Dec 03, 2024


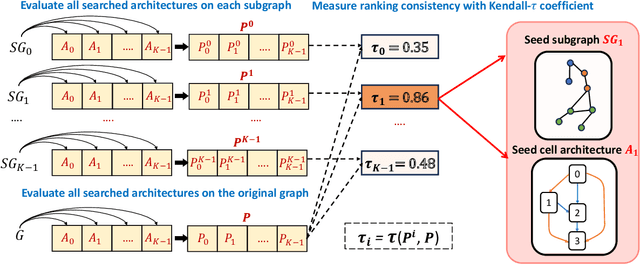
GNAS (Graph Neural Architecture Search) has demonstrated great effectiveness in automatically designing the optimal graph neural architectures for multiple downstream tasks, such as node classification and link prediction. However, most existing GNAS methods cannot efficiently handle large-scale graphs containing more than million-scale nodes and edges due to the expensive computational and memory overhead. To scale GNAS on large graphs while achieving better performance, we propose SA-GNAS, a novel framework based on seed architecture expansion for efficient large-scale GNAS. Similar to the cell expansion in biotechnology, we first construct a seed architecture and then expand the seed architecture iteratively. Specifically, we first propose a performance ranking consistency-based seed architecture selection method, which selects the architecture searched on the subgraph that best matches the original large-scale graph. Then, we propose an entropy minimization-based seed architecture expansion method to further improve the performance of the seed architecture. Extensive experimental results on five large-scale graphs demonstrate that the proposed SA-GNAS outperforms human-designed state-of-the-art GNN architectures and existing graph NAS methods. Moreover, SA-GNAS can significantly reduce the search time, showing better search efficiency. For the largest graph with billion edges, SA-GNAS can achieve 2.8 times speedup compared to the SOTA large-scale GNAS method GAUSS. Additionally, since SA-GNAS is inherently parallelized, the search efficiency can be further improved with more GPUs. SA-GNAS is available at https://github.com/PasaLab/SAGNAS.
Arguments to Key Points Mapping with Prompt-based Learning
Nov 28, 2022



Handling and digesting a huge amount of information in an efficient manner has been a long-term demand in modern society. Some solutions to map key points (short textual summaries capturing essential information and filtering redundancies) to a large number of arguments/opinions have been provided recently (Bar-Haim et al., 2020). To complement the full picture of the argument-to-keypoint mapping task, we mainly propose two approaches in this paper. The first approach is to incorporate prompt engineering for fine-tuning the pre-trained language models (PLMs). The second approach utilizes prompt-based learning in PLMs to generate intermediary texts, which are then combined with the original argument-keypoint pairs and fed as inputs to a classifier, thereby mapping them. Furthermore, we extend the experiments to cross/in-domain to conduct an in-depth analysis. In our evaluation, we find that i) using prompt engineering in a more direct way (Approach 1) can yield promising results and improve the performance; ii) Approach 2 performs considerably worse than Approach 1 due to the negation issue of the PLM.