 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2:Cross learning module enhanced decision transformer with Constraint-aware loss for auto-bidding
Jan 29, 2026Decision Transformer (DT) shows promise for generative auto-bidding by capturing temporal dependencies, but suffers from two critical limitations: insufficient cross-correlation modeling among state, action, and return-to-go (RTG) sequences, and indiscriminate learning of optimal/suboptimal behaviors. To address these, we propose C2, a novel framework enhancing DT with two core innovations: (1) a Cross Learning Block (CLB) via cross-attention to strengthen inter-sequence correlation modeling; (2) a Constraint-aware Loss (CL) incorporating budget and Cost-Per-Acquisition (CPA) constraints for selective learning of optimal trajectories. Extensive offline evaluations on the AuctionNet dataset demonstrate consistent performance gains (up to 3.2% over state-of-the-art method) across diverse budget settings; ablation studies verify the complementary synergy of CLB and CL, confirming C2's superiority in auto-bidding. The code for reproducing our results is available at: https://github.com/Dingjinren/C2.
PrunePEFT: Iterative Hybrid Pruning for Parameter-Efficient Fine-tuning of LLMs
Jun 09, 2025Parameter Efficient Fine-Tuning (PEFT) methods have emerged as effective and promising approaches for fine-tuning pre-trained language models. Compared with Full parameter Fine-Tuning (FFT), PEFT achieved comparable task performance with a substantial reduction of trainable parameters, which largely saved the training and storage costs. However, using the PEFT method requires considering a vast design space, such as the type of PEFT modules and their insertion layers. Inadequate configurations can lead to sub-optimal results. Conventional solutions such as architectural search techniques, while effective, tend to introduce substantial additional overhead. In this paper, we propose a novel approach, PrunePEFT, which formulates the PEFT strategy search as a pruning problem and introduces a hybrid pruning strategy that capitalizes on the sensitivity of pruning methods to different PEFT modules. This method extends traditional pruning techniques by iteratively removing redundant or conflicting PEFT modules, thereby optimizing the fine-tuned configuration. By efficiently identifying the most relevant modules, our approach significantly reduces the computational burden typically associated with architectural search processes, making it a more scalable and efficient solution for fine-tuning large pre-trained models.
HCMRM: A High-Consistency Multimodal Relevance Model for Search Ads
Feb 09, 2025



Search advertising is essential for merchants to reach the target users on short video platforms. Short video ads aligned with user search intents are displayed through relevance matching and bid ranking mechanisms. This paper focuses on improving query-to-video relevance matching to enhance the effectiveness of ranking in ad systems. Recent vision-language pre-training models have demonstrated promise in various multimodal tasks. However, their contribution to downstream query-video relevance tasks is limited, as the alignment between the pair of visual signals and text differs from the modeling of the triplet of the query, visual signals, and video text. In addition, our previous relevance model provides limited ranking capabilities, largely due to the discrepancy between the binary cross-entropy fine-tuning objective and the ranking objective. To address these limitations, we design a high-consistency multimodal relevance model (HCMRM). It utilizes a simple yet effective method to enhance the consistency between pre-training and relevance tasks. Specifically, during the pre-training phase, along with aligning visual signals and video text, several keywords are extracted from the video text as pseudo-queries to perform the triplet relevance modeling. For the fine-tuning phase, we introduce a hierarchical softmax loss, which enables the model to learn the order within labels while maximizing the distinction between positive and negative samples. This promotes the fusion ranking of relevance and bidding in the subsequent ranking stage. The proposed method has been deployed in the Kuaishou search advertising system for over a year, contributing to a 6.1% reduction in the proportion of irrelevant ads and a 1.4% increase in ad revenue.
End-to-end training of Multimodal Model and ranking Model
Apr 09, 2024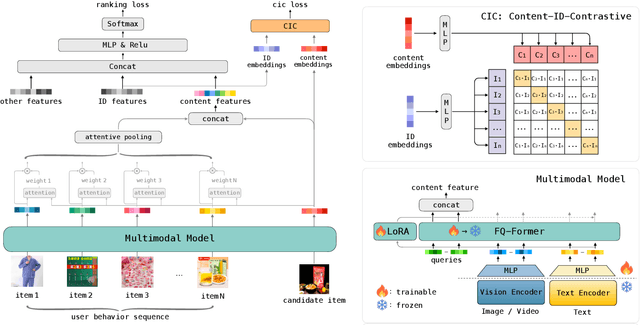
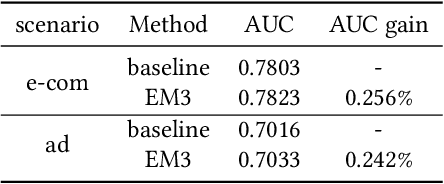
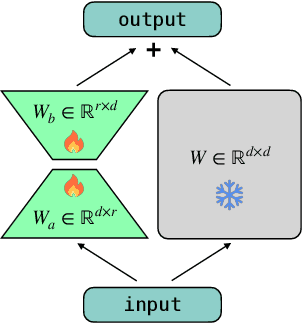
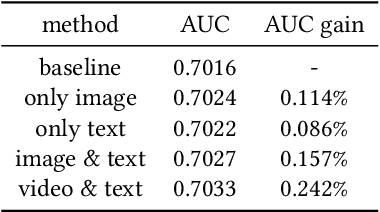
Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.