 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end training of Multimodal Model and ranking Model
Apr 09, 2024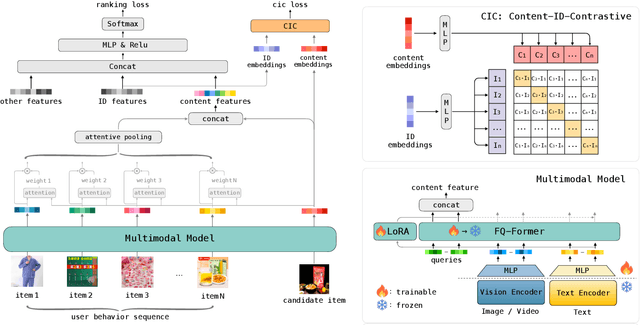
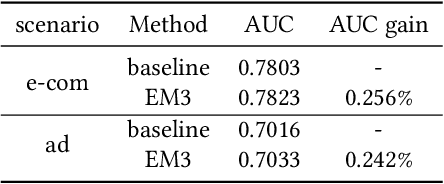
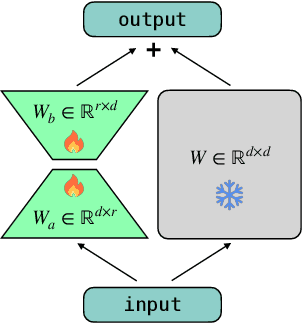
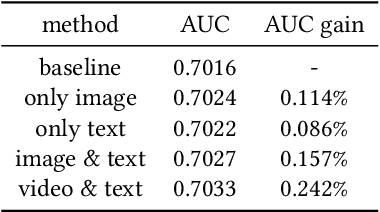
Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.