 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Latent Alignment for Interpretable Radar Based Occupancy Detection in Ambient Assisted Living
Jan 27, 2026In this work, we study how to make mmWave radar presence detection more interpretable for Ambient Assisted Living (AAL) settings, where camera-based sensing raises privacy concerns. We propose a Generative Latent Alignment (GLA) framework that combines a lightweight convolutional variational autoencoder with a frozen CLIP text encoder to learn a low-dimensional latent representation of radar Range-Angle (RA) heatmaps. The latent space is softly aligned with two semantic anchors corresponding to "empty room" and "person present", and Grad-CAM is applied in this aligned latent space to visualize which spatial regions support each presence decision. On our mmWave radar dataset, we qualitatively observe that the "person present" class produces compact Grad-CAM blobs that coincide with strong RA returns, whereas "empty room" samples yield diffuse or no evidence. We also conduct an ablation study using unrelated text prompts, which degrades both reconstruction and localization, suggesting that radar-specific anchors are important for meaningful explanations in this setting.
A Physics-Informed Digital Twin Framework for Calibrated Sim-to-Real FMCW Radar Occupancy Estimation
Jan 25, 2026Learning robust radar perception models directly from real measurements is costly due to the need for controlled experiments, repeated calibration, and extensive annotation. This paper proposes a lightweight simulation-to-real (sim2real) framework that enables reliable Frequency Modulated Continuous Wave (FMCW) radar occupancy detection and people counting using only a physics-informed geometric simulator and a small unlabeled real calibration set. We introduce calibrated domain randomization (CDR) to align the global noise-floor statistics of simulated range-Doppler (RD) maps with those observed in real environments while preserving discriminative micro-Doppler structure. Across real-world evaluations, ResNet18 models trained purely on CDR-adjusted simulation achieve 97 percent accuracy for occupancy detection and 72 percent accuracy for people counting, outperforming ray-tracing baseline simulation and conventional random domain randomization baselines.
Doppler-Domain Respiratory Amplification for Semi-Static Human Occupancy Detection Using Low-Resolution SIMO FMCW Radar
Jan 25, 2026Radar-based sensing is a promising privacy-preserving alternative to cameras and wearables in settings such as long-term care. Yet detecting quasi-static presence (lying, sitting, or standing with only subtle micro-motions) is difficult for low-resolution SIMO FMCW radar because near-zero Doppler energy is often buried under static clutter. We present Respiratory-Amplification Semi-Static Occupancy (RASSO), an invertible Doppler-domain non-linear remapping that densifies the slow-time FFT (Doppler) grid around 0 m/s before adaptive Capon beamforming. The resulting range-azimuth (RA) maps exhibit higher effective SNR, sharper target peaks, and lower background variance, making thresholding and learning more reliable. On a real nursing-home dataset collected with a short-range 1Tx-3Rx radar, RASSO-RA improves classical detection performance, achieving AUC = 0.981 and recall = 0.920/0.947 at FAR = 1%/5%, outperforming conventional Capon processing and a recent baseline. RASSO-RA also benefits data-driven models: a frame-based CNN reaches 95-99% accuracy and a sequence-based CNN-LSTM reaches 99.4-99.6% accuracy across subjects. A paired session-level bootstrap test confirms statistically significant macro-F1 gains of 2.6-3.6 points (95% confidence intervals above zero) over the non-warped pipeline. These results show that simple Doppler-domain warping before spatial processing can materially improve semi-static occupancy detection with low-resolution radar in real clinical environments.
Reliable Quasi-Static Post-Fall Floor-Occupancy Detection Using Low-Cost Millimetre-Wave Radar
Jan 25, 2026As the population ages rapidly, long-term care (LTC) facilities across North America face growing pressure to monitor residents safely while keeping staff workload manageable. Falls are among the most critical events to monitor due to their timely response requirement, yet frequent false alarms or uncertain detections can overwhelm caregivers and contribute to alarm fatigue. This motivates the design of reliable, whole end-to-end ambient monitoring systems from occupancy and activity awareness to fall and post-fall detection. In this paper, we focus on robust post-fall floor-occupancy detection using an off-the-shelf 60 GHz FMCW radar and evaluate its deployment in a realistic, furnished indoor environment representative of LTC facilities. Post-fall detection is challenging since motion is minimal, and reflections from the floor and surrounding objects can dominate the radar signal return. We compare a vendor-provided digital beamforming (DBF) pipeline against a proposed preprocessing approach based on Capon or minimum variance distortionless response (MVDR) beamforming. A cell-averaging constant false alarm rate (CA-CFAR) detector is applied and evaluated on the resulting range-azimuth maps across 7 participants. The proposed method improves the mean frame-positive rate from 0.823 (DBF) to 0.916 (Proposed).
Radar-Based Fall Detection for Assisted Living: A Digital-Twin Representation Case Study
Jan 17, 2026Obtaining data on high-impact falls from older adults is ethically difficult, yet these rare events cause many fall-related health problems. As a result, most radar-based fall detectors are trained on staged falls from young volunteers, and representation choices are rarely tested against the radar signals from dangerous falls. This paper uses a frequency-modulated continuous-wave (FMCW) radar digital twin as a single simulated room testbed to study how representation choice affects fall/non-fall discrimination. From the same simulated range-Doppler sequence, Doppler-time spectrograms, three-channel per-receiver spectrogram stacks, and time-pooled range-Doppler maps (RDMs) are derived and fed to an identical compact CNN under matched training on a balanced fall/non-fall dataset. In this twin, temporal spectrograms reach 98-99% test accuracy with similar precision and recall for both classes, while static RDMs reach 89.4% and show more variable training despite using the same backbone. A qualitative comparison between synthetic and measured fall spectrograms suggests that the twin captures gross Doppler-time structure, but amplitude histograms reveal differences in the distributions of amplitude values consistent with receiver processing not modeled in the twin. Because the twin omits noise and hardware impairments and is only qualitatively compared to a single measured example, these results provide representation-level guidance under controlled synthetic conditions rather than ready-to-use clinical performance in real settings.
CovHuSeg: An Enhanced Approach for Kidney Pathology Segmentation
Nov 28, 2024



Segmentation has long been essential in computer vision due to its numerous real-world applications. However, most traditional deep learning and machine learning models need help to capture geometric features such as size and convexity of the segmentation targets, resulting in suboptimal outcomes. To resolve this problem, we propose using a CovHuSeg algorithm to solve the problem of kidney glomeruli segmentation. This simple post-processing method is specified to adapt to the segmentation of ball-shaped anomalies, including the glomerulus. Unlike other post-processing methods, the CovHuSeg algorithm assures that the outcome mask does not have holes in it or comes in unusual shapes that are impossible to be the shape of a glomerulus. We illustrate the effectiveness of our method by experimenting with multiple deep-learning models in the context of segmentation on kidney pathology images. The results show that all models have increased accuracy when using the CovHuSeg algorithm.
Partial Membership Latent Dirichlet Allocation
Dec 28, 2016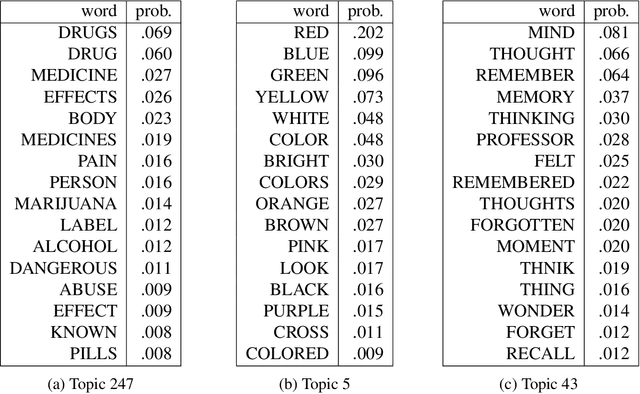

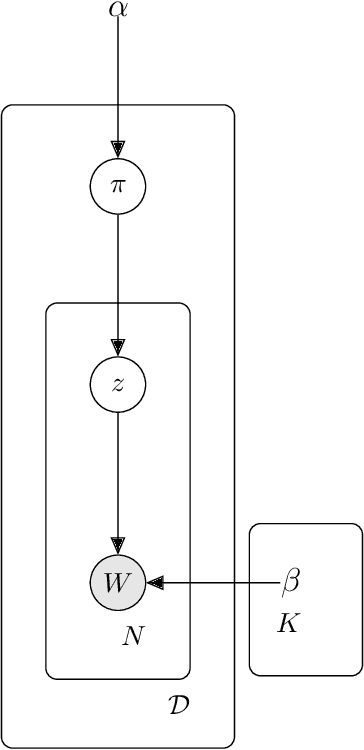
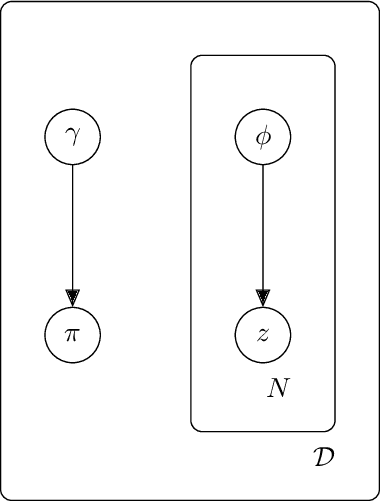
Topic models (e.g., pLSA, LDA, sLDA) have been widely used for segmenting imagery. However, these models are confined to crisp segmentation, forcing a visual word (i.e., an image patch) to belong to one and only one topic. Yet, there are many images in which some regions cannot be assigned a crisp categorical label (e.g., transition regions between a foggy sky and the ground or between sand and water at a beach). In these cases, a visual word is best represented with partial memberships across multiple topics. To address this, we present a partial membership latent Dirichlet allocation (PM-LDA) model and an associated parameter estimation algorithm. This model can be useful for imagery where a visual word may be a mixture of multiple topics. Experimental results on visual and sonar imagery show that PM-LDA can produce both crisp and soft semantic image segmentations; a capability previous topic modeling methods do not have.