 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Detection and Segmentation in Circular-Scan Synthetic-Aperture-Sonar Images using Semi-Supervised Convolutional Encoder-Decoders
Jan 10, 2021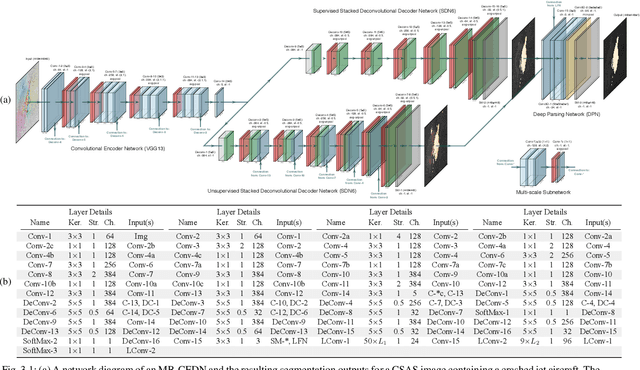
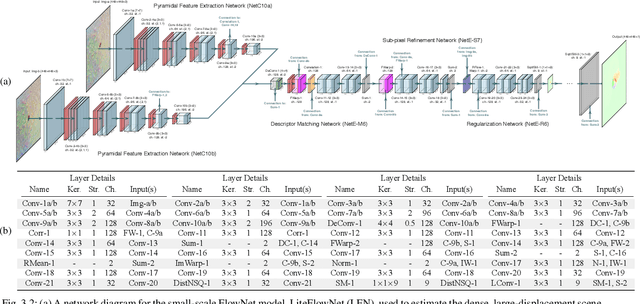
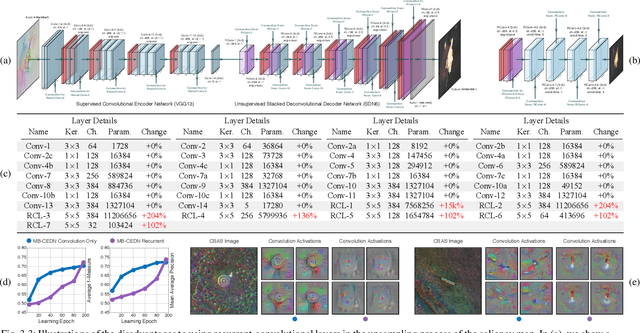
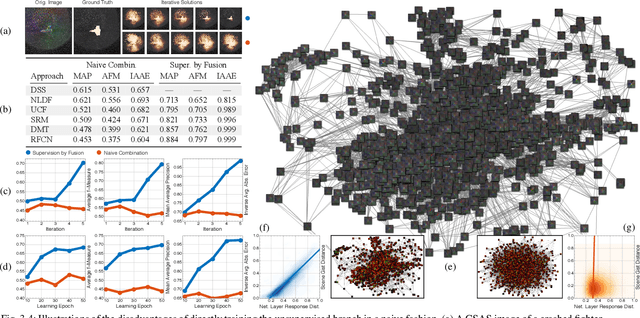
We propose a saliency-based, multi-target detection and segmentation framework for multi-aspect, semi-coherent imagery formed from circular-scan, synthetic-aperture sonar (CSAS). Our framework relies on a multi-branch, convolutional encoder-decoder network (MB-CEDN). The encoder portion extracts features from one or more CSAS images of the targets. These features are then split off and fed into multiple decoders that perform pixel-level classification on the extracted features to roughly mask the target in an unsupervised-trained manner and detect foreground and background pixels in a supervised-trained manner. Each of these target-detection estimates provide different perspectives as to what constitute a target. These opinions are cascaded into a deep-parsing network to model contextual and spatial constraints that help isolate targets better than either solution estimate alone. We evaluate our framework using real-world CSAS data with five broad target classes. Since we are the first to consider both CSAS target detection and segmentation, we adapt existing image and video-processing network topologies from the literature for comparative purposes. We show that our framework outperforms supervised deep networks. It greatly outperforms state-of-the-art unsupervised approaches for diverse target and seafloor types.
Partial Membership Latent Dirichlet Allocation
Dec 28, 2016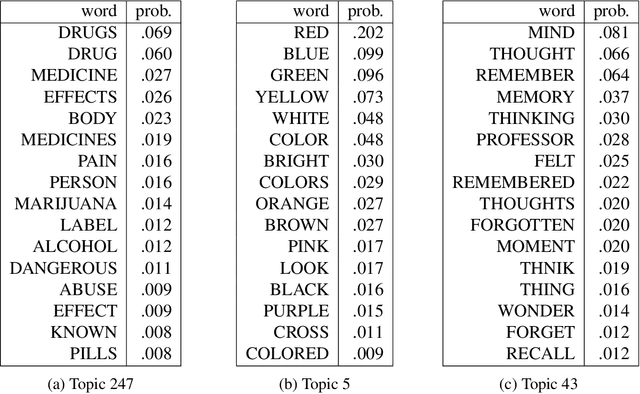

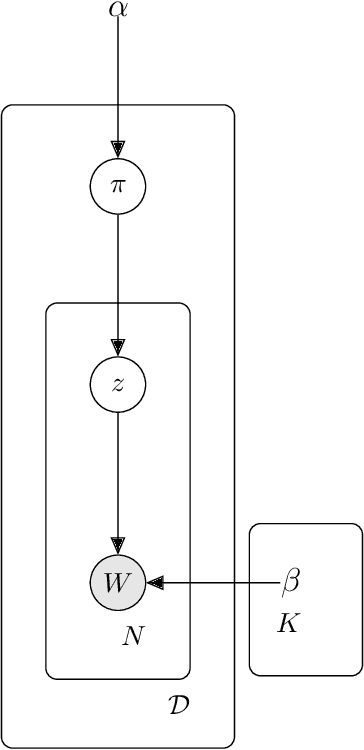
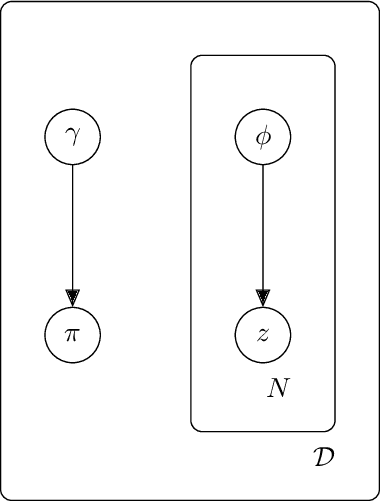
Topic models (e.g., pLSA, LDA, sLDA) have been widely used for segmenting imagery. However, these models are confined to crisp segmentation, forcing a visual word (i.e., an image patch) to belong to one and only one topic. Yet, there are many images in which some regions cannot be assigned a crisp categorical label (e.g., transition regions between a foggy sky and the ground or between sand and water at a beach). In these cases, a visual word is best represented with partial memberships across multiple topics. To address this, we present a partial membership latent Dirichlet allocation (PM-LDA) model and an associated parameter estimation algorithm. This model can be useful for imagery where a visual word may be a mixture of multiple topics. Experimental results on visual and sonar imagery show that PM-LDA can produce both crisp and soft semantic image segmentations; a capability previous topic modeling methods do not have.