 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Semantic Segmentation of Circular-Scan, Synthetic-Aperture-Sonar Imagery
Jan 20, 2024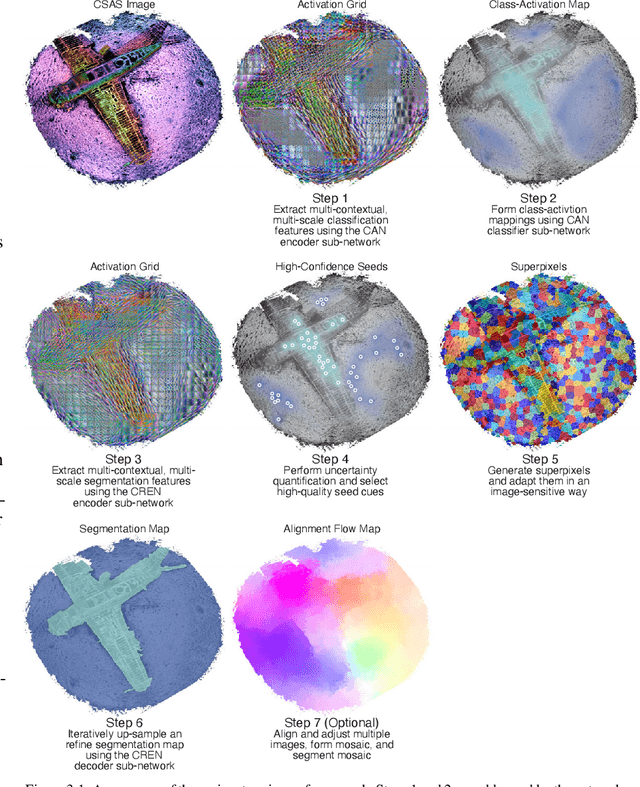
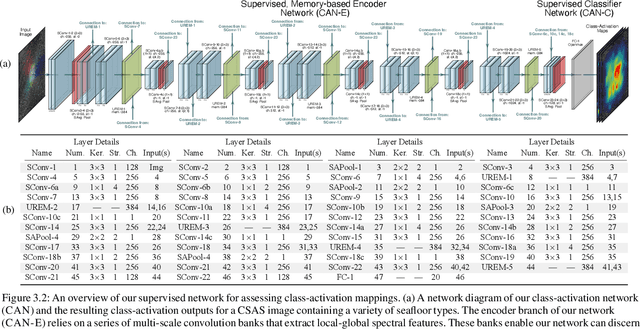
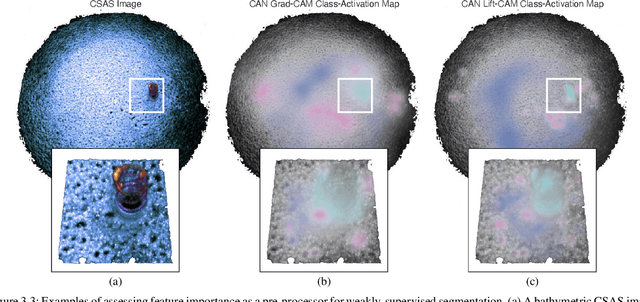
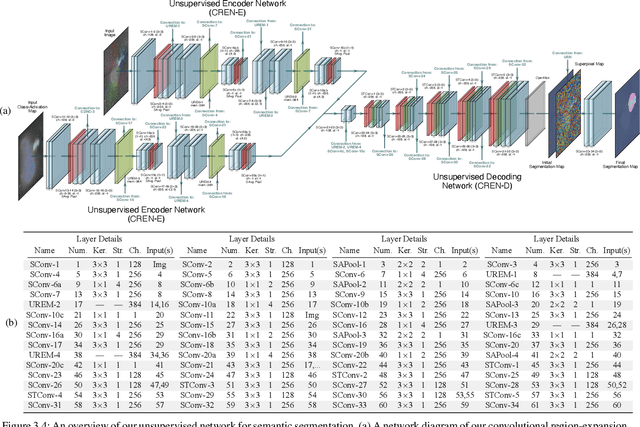
We propose a weakly-supervised framework for the semantic segmentation of circular-scan synthetic-aperture-sonar (CSAS) imagery. The first part of our framework is trained in a supervised manner, on image-level labels, to uncover a set of semi-sparse, spatially-discriminative regions in each image. The classification uncertainty of each region is then evaluated. Those areas with the lowest uncertainties are then chosen to be weakly labeled segmentation seeds, at the pixel level, for the second part of the framework. Each of the seed extents are progressively resized according to an unsupervised, information-theoretic loss with structured-prediction regularizers. This reshaping process uses multi-scale, adaptively-weighted features to delineate class-specific transitions in local image content. Content-addressable memories are inserted at various parts of our framework so that it can leverage features from previously seen images to improve segmentation performance for related images. We evaluate our weakly-supervised framework using real-world CSAS imagery that contains over ten seafloor classes and ten target classes. We show that our framework performs comparably to nine fully-supervised deep networks. Our framework also outperforms eleven of the best weakly-supervised deep networks. We achieve state-of-the-art performance when pre-training on natural imagery. The average absolute performance gap to the next-best weakly-supervised network is well over ten percent for both natural imagery and sonar imagery. This gap is found to be statistically significant.
Adapting the Exploration Rate for Value-of-Information-Based Reinforcement Learning
Dec 31, 2022
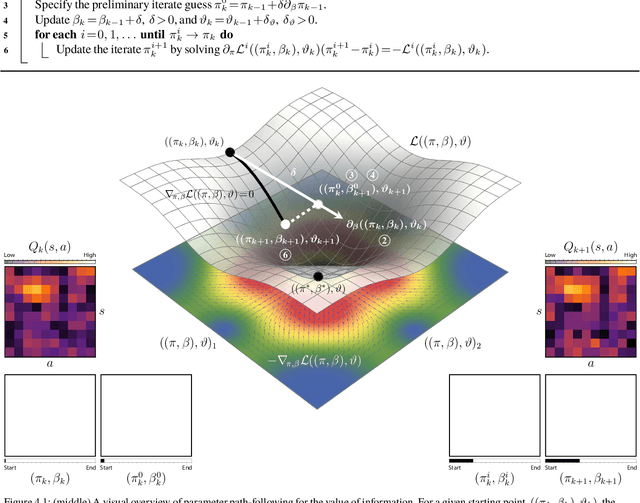
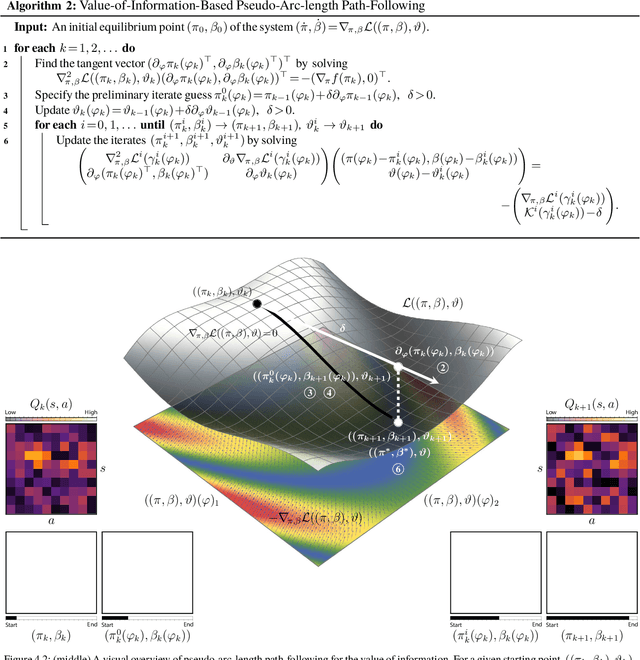
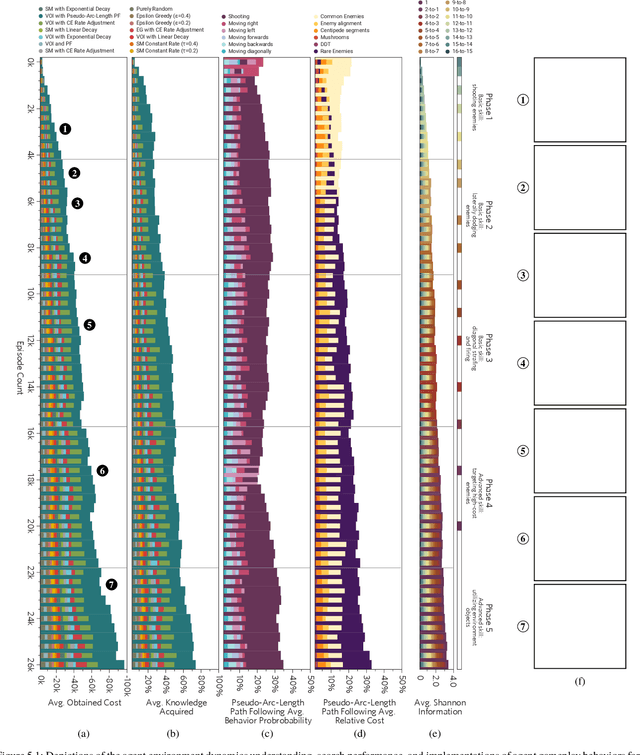
In this paper, we consider the problem of adjusting the exploration rate when using value-of-information-based exploration. We do this by converting the value-of-information optimization into a problem of finding equilibria of a flow for a changing exploration rate. We then develop an efficient path-following scheme for converging to these equilibria and hence uncovering optimal action-selection policies. Under this scheme, the exploration rate is automatically adapted according to the agent's experiences. Global convergence is theoretically assured. We first evaluate our exploration-rate adaptation on the Nintendo GameBoy games Centipede and Millipede. We demonstrate aspects of the search process, like that it yields a hierarchy of state abstractions. We also show that our approach returns better policies in fewer episodes than conventional search strategies relying on heuristic, annealing-based exploration-rate adjustments. We then illustrate that these trends hold for deep, value-of-information-based agents that learn to play ten simple games and over forty more complicated games for the Nintendo GameBoy system. Performance either near or well above the level of human play is observed.
Estimating Rényi's $α$-Cross-Entropies in a Matrix-Based Way
Sep 24, 2021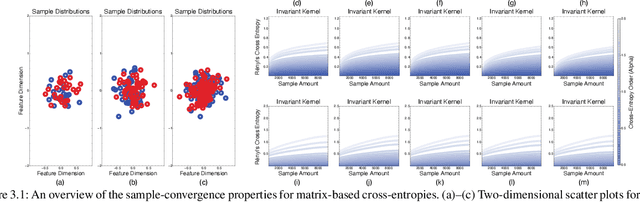
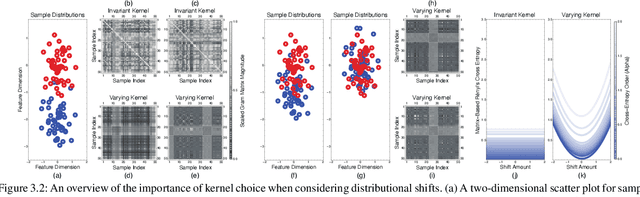
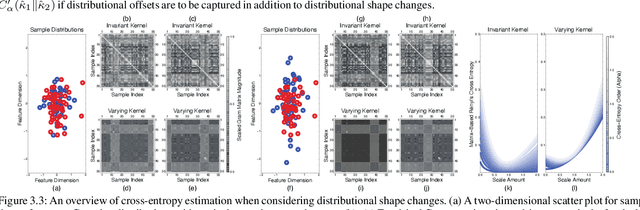
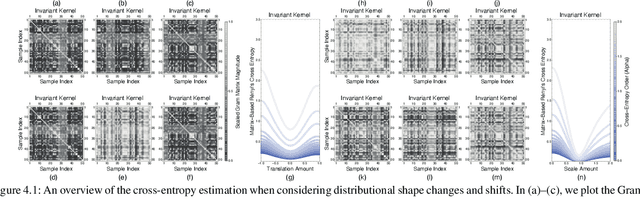
Conventional information-theoretic quantities assume access to probability distributions. Estimating such distributions is not trivial. Here, we consider function-based formulations of cross entropy that sidesteps this a priori estimation requirement. We propose three measures of R\'enyi's $\alpha$-cross-entropies in the setting of reproducing-kernel Hilbert spaces. Each measure has its appeals. We prove that we can estimate these measures in an unbiased, non-parametric, and minimax-optimal way. We do this via sample-constructed Gram matrices. This yields matrix-based estimators of R\'enyi's $\alpha$-cross-entropies. These estimators satisfy all of the axioms that R\'enyi established for divergences. Our cross-entropies can thus be used for assessing distributional differences. They are also appropriate for handling high-dimensional distributions, since the convergence rate of our estimator is independent of the sample dimensionality. Python code for implementing these measures can be found at https://github.com/isledge/MBRCE
External-Memory Networks for Low-Shot Learning of Targets in Forward-Looking-Sonar Imagery
Jul 22, 2021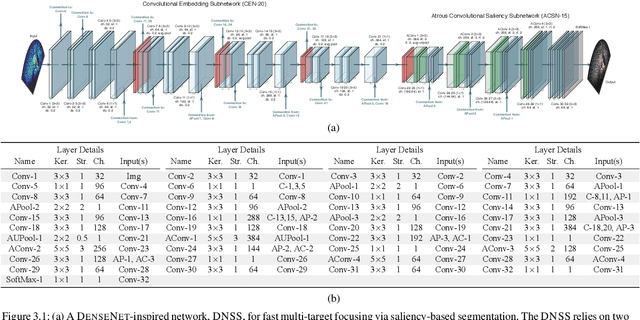
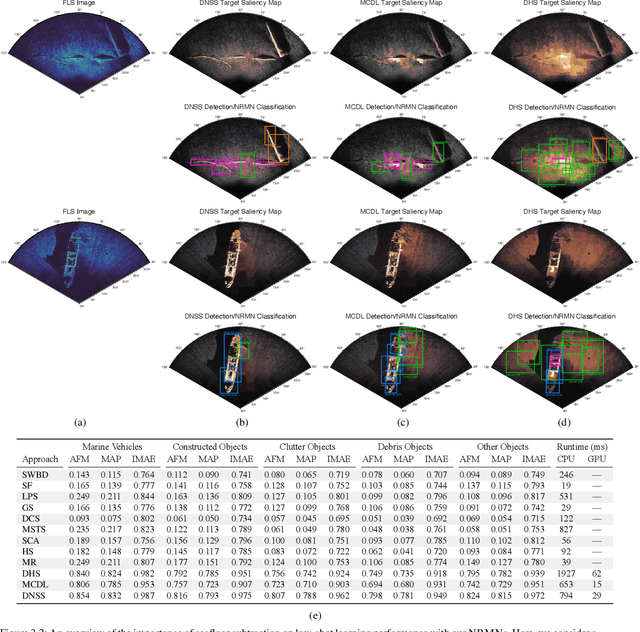
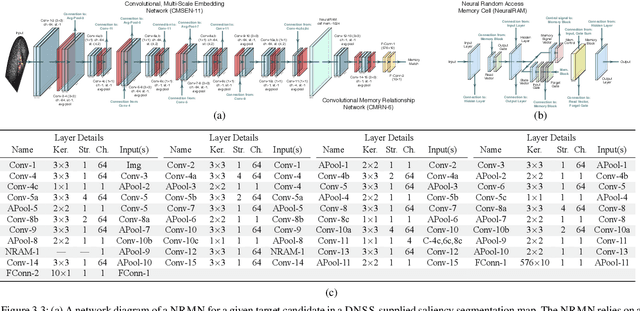
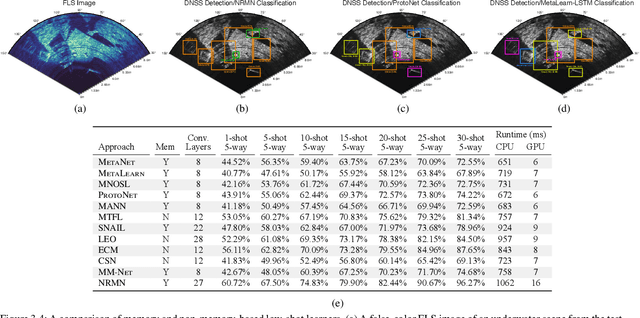
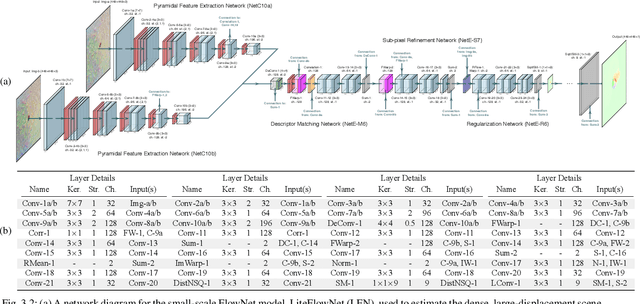
We propose a memory-based framework for real-time, data-efficient target analysis in forward-looking-sonar (FLS) imagery. Our framework relies on first removing non-discriminative details from the imagery using a small-scale DenseNet-inspired network. Doing so simplifies ensuing analyses and permits generalizing from few labeled examples. We then cascade the filtered imagery into a novel NeuralRAM-based convolutional matching network, NRMN, for low-shot target recognition. We employ a small-scale FlowNet, LFN to align and register FLS imagery across local temporal scales. LFN enables target label consensus voting across images and generally improves target detection and recognition rates. We evaluate our framework using real-world FLS imagery with multiple broad target classes that have high intra-class variability and rich sub-class structure. We show that few-shot learning, with anywhere from ten to thirty class-specific exemplars, performs similarly to supervised deep networks trained on hundreds of samples per class. Effective zero-shot learning is also possible. High performance is realized from the inductive-transfer properties of NRMNs when distractor elements are removed.
An Information-Theoretic Approach for Automatically Determining the Number of States when Aggregating Markov Chains
Jul 05, 2021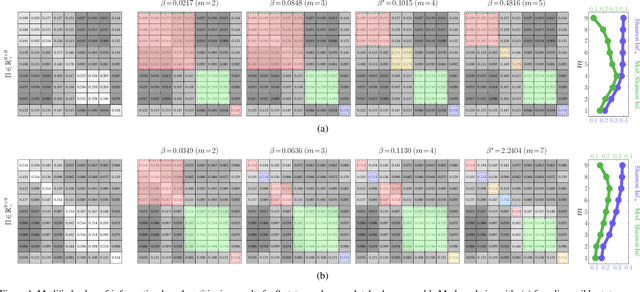
A fundamental problem when aggregating Markov chains is the specification of the number of state groups. Too few state groups may fail to sufficiently capture the pertinent dynamics of the original, high-order Markov chain. Too many state groups may lead to a non-parsimonious, reduced-order Markov chain whose complexity rivals that of the original. In this paper, we show that an augmented value-of-information-based approach to aggregating Markov chains facilitates the determination of the number of state groups. The optimal state-group count coincides with the case where the complexity of the reduced-order chain is balanced against the mutual dependence between the original- and reduced-order chain dynamics.
Annotating Motion Primitives for Simplifying Action Search in Reinforcement Learning
Feb 24, 2021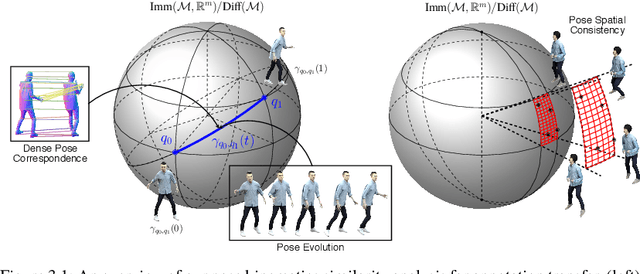
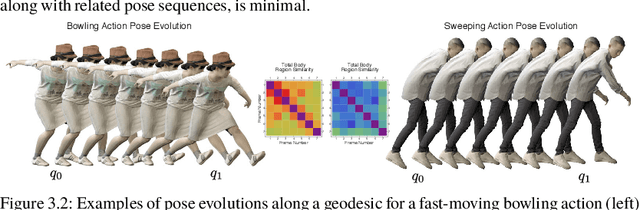
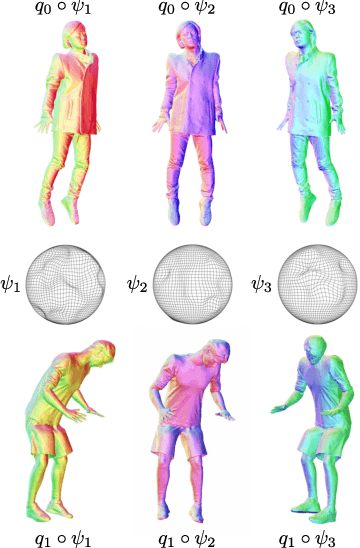
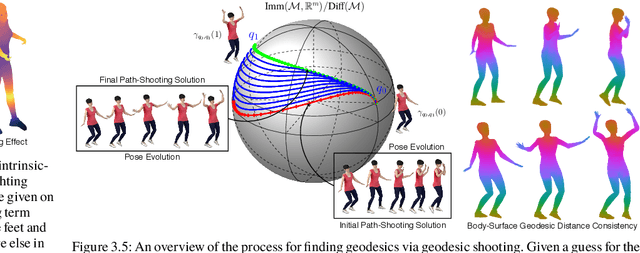
Reinforcement learning in large-scale environments is challenging due to the many possible actions that can be taken in specific situations. We have previously developed a means of constraining, and hence speeding up, the search process through the use of motion primitives; motion primitives are sequences of pre-specified actions taken across a state series. As a byproduct of this work, we have found that if the motion primitives' motions and actions are labeled, then the search can be sped up further. Since motion primitives may initially lack such details, we propose a theoretically viewpoint-insensitive and speed-insensitive means of automatically annotating the underlying motions and actions. We do this through a differential-geometric, spatio-temporal kinematics descriptor, which analyzes how the poses of entities in two motion sequences change over time. We use this descriptor in conjunction with a weighted-nearest-neighbor classifier to label the primitives using a limited set of training examples. In our experiments, we achieve high motion and action annotation rates for human-action-derived primitives with as few as one training sample. We also demonstrate that reinforcement learning using accurately labeled trajectories leads to high-performing policies more quickly than standard reinforcement learning techniques. This is partly because motion primitives encode prior domain knowledge and preempt the need to re-discover that knowledge during training. It is also because agents can leverage the labels to systematically ignore action classes that do not facilitate task objectives, thereby reducing the action space.
Faster Convergence in Deep-Predictive-Coding Networks to Learn Deeper Representations
Feb 05, 2021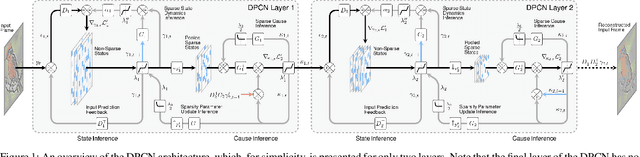
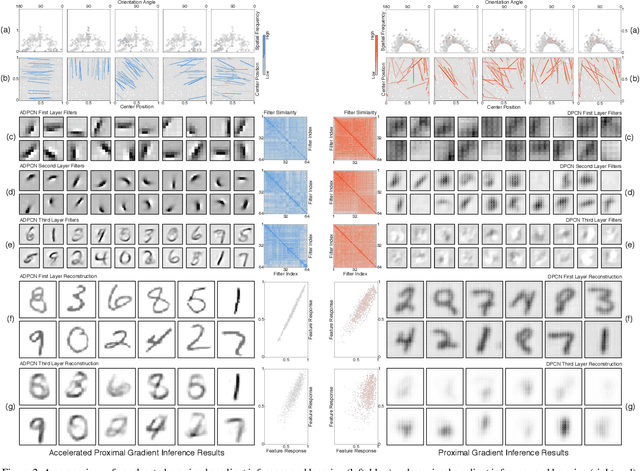


Deep-predictive-coding networks (DPCNs) are hierarchical, generative models that rely on feed-forward and feed-back connections to modulate latent feature representations of stimuli in a dynamic and context-sensitive manner. A crucial element of DPCNs is a forward-backward inference procedure to uncover sparse states of a dynamic model, which are used for invariant feature extraction. However, this inference and the corresponding backwards network parameter updating are major computational bottlenecks. They severely limit the network depths that can be reasonably implemented and easily trained. We therefore propose an optimization strategy, with better empirical and theoretical convergence, based on accelerated proximal gradients. We demonstrate that the ability to construct deeper DPCNs leads to receptive fields that capture well the entire notions of objects on which the networks are trained. This improves the feature representations. It yields completely unsupervised classifiers that surpass convolutional and convolutional-recurrent autoencoders and are on par with convolutional networks trained in a supervised manner. This is despite the DPCNs having orders of magnitude fewer parameters.
Target Detection and Segmentation in Circular-Scan Synthetic-Aperture-Sonar Images using Semi-Supervised Convolutional Encoder-Decoders
Jan 10, 2021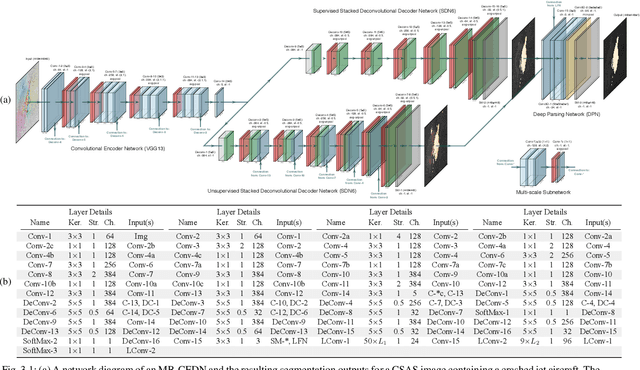
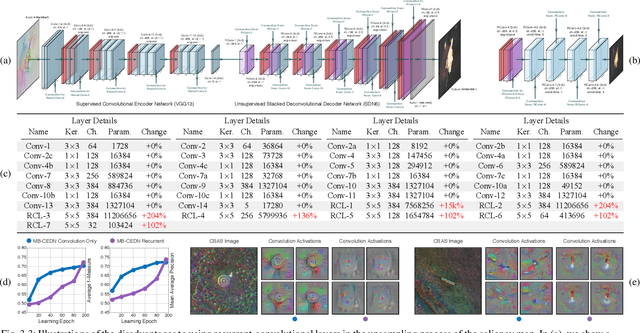
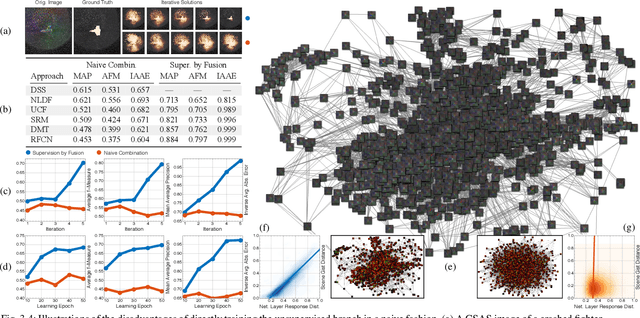
We propose a saliency-based, multi-target detection and segmentation framework for multi-aspect, semi-coherent imagery formed from circular-scan, synthetic-aperture sonar (CSAS). Our framework relies on a multi-branch, convolutional encoder-decoder network (MB-CEDN). The encoder portion extracts features from one or more CSAS images of the targets. These features are then split off and fed into multiple decoders that perform pixel-level classification on the extracted features to roughly mask the target in an unsupervised-trained manner and detect foreground and background pixels in a supervised-trained manner. Each of these target-detection estimates provide different perspectives as to what constitute a target. These opinions are cascaded into a deep-parsing network to model contextual and spatial constraints that help isolate targets better than either solution estimate alone. We evaluate our framework using real-world CSAS data with five broad target classes. Since we are the first to consider both CSAS target detection and segmentation, we adapt existing image and video-processing network topologies from the literature for comparative purposes. We show that our framework outperforms supervised deep networks. It greatly outperforms state-of-the-art unsupervised approaches for diverse target and seafloor types.
An Exact Reformulation of Feature-Vector-based Radial-Basis-Function Networks for Graph-based Observations
Jan 22, 2019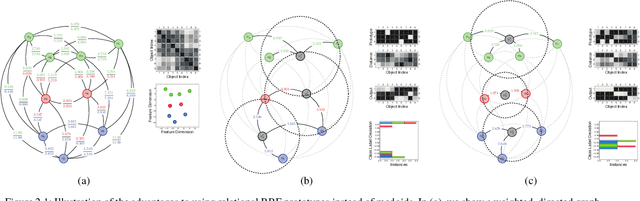
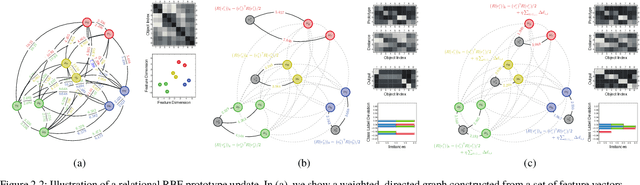
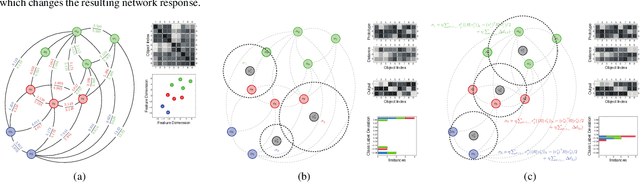
Radial-basis-function networks are traditionally defined for sets of vector-based observations. In this short paper, we reformulate such networks so that they can be applied to adjacency-matrix representations of weighted, directed graphs that represent the relationships between object pairs. We re-state the sum-of-squares objective function so that it is purely dependent on entries from the adjacency matrix. From this objective function, we derive a gradient descent update for the network weights. We also derive a gradient update that simulates the repositioning of the radial basis prototypes and changes in the radial basis prototype parameters. An important property of our radial basis function networks is that they are guaranteed to yield the same responses as conventional radial-basis networks trained on a corresponding vector realization of the relationships encoded by the adjacency-matrix. Such a vector realization only needs to provably exist for this property to hold, which occurs whenever the relationships correspond to distances from some arbitrary metric applied to a latent set of vectors. We therefore completely avoid needing to actually construct vectorial realizations via multi-dimensional scaling, which ensures that the underlying relationships are totally preserved.
An Analysis of the Value of Information when Exploring Stochastic, Discrete Multi-Armed Bandits
Mar 03, 2018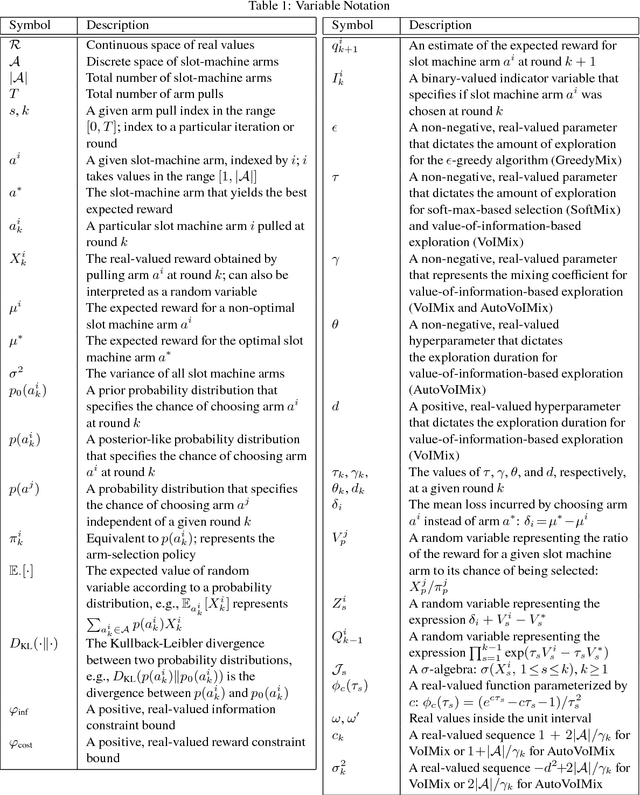
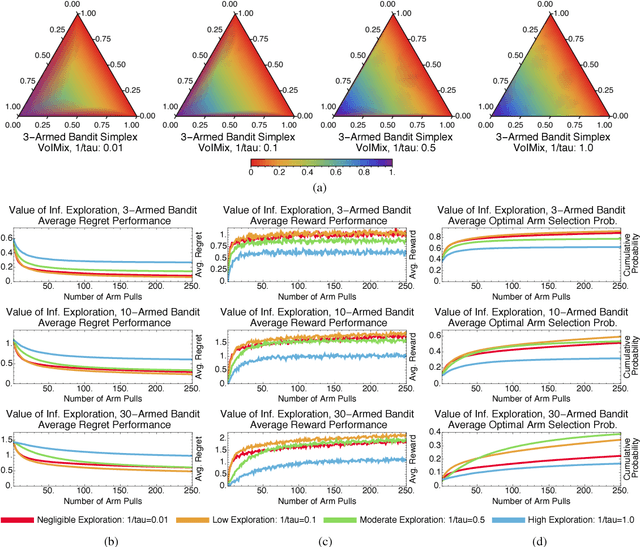
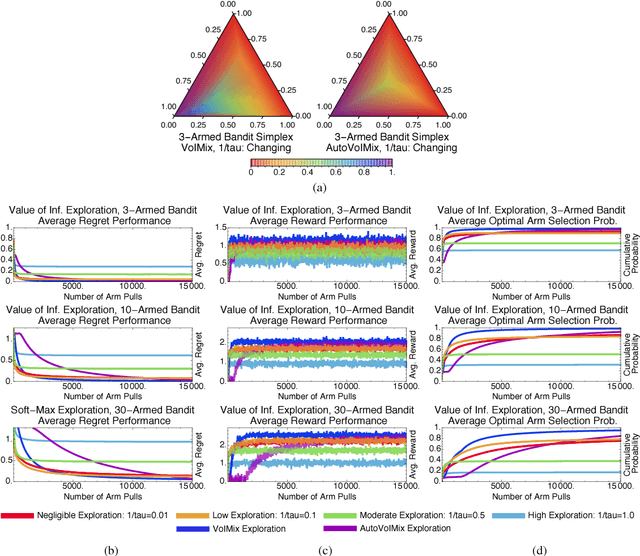
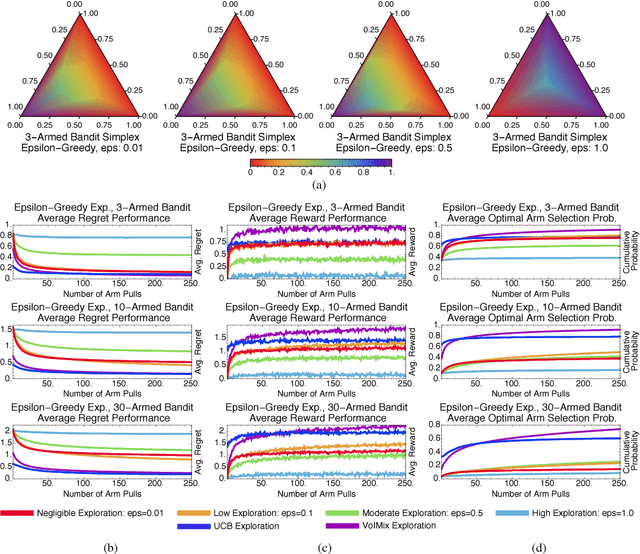
In this paper, we propose an information-theoretic exploration strategy for stochastic, discrete multi-armed bandits that achieves optimal regret. Our strategy is based on the value of information criterion. This criterion measures the trade-off between policy information and obtainable rewards. High amounts of policy information are associated with exploration-dominant searches of the space and yield high rewards. Low amounts of policy information favor the exploitation of existing knowledge. Information, in this criterion, is quantified by a parameter that can be varied during search. We demonstrate that a simulated-annealing-like update of this parameter, with a sufficiently fast cooling schedule, leads to an optimal regret that is logarithmic with respect to the number of episodes.