 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Convergence in Deep-Predictive-Coding Networks to Learn Deeper Representations
Paper and Code
Feb 05, 2021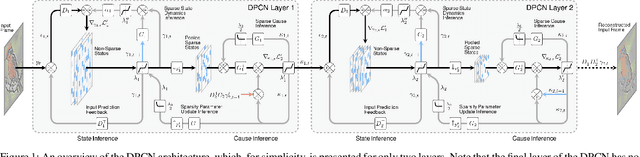
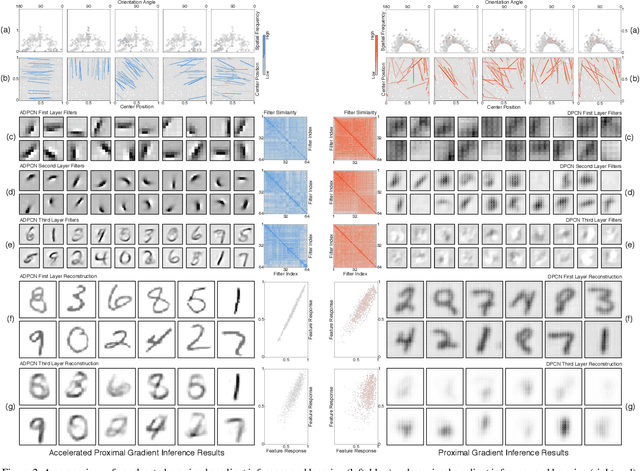


Deep-predictive-coding networks (DPCNs) are hierarchical, generative models that rely on feed-forward and feed-back connections to modulate latent feature representations of stimuli in a dynamic and context-sensitive manner. A crucial element of DPCNs is a forward-backward inference procedure to uncover sparse states of a dynamic model, which are used for invariant feature extraction. However, this inference and the corresponding backwards network parameter updating are major computational bottlenecks. They severely limit the network depths that can be reasonably implemented and easily trained. We therefore propose an optimization strategy, with better empirical and theoretical convergence, based on accelerated proximal gradients. We demonstrate that the ability to construct deeper DPCNs leads to receptive fields that capture well the entire notions of objects on which the networks are trained. This improves the feature representations. It yields completely unsupervised classifiers that surpass convolutional and convolutional-recurrent autoencoders and are on par with convolutional networks trained in a supervised manner. This is despite the DPCNs having orders of magnitude fewer parameters.