 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Detection and Segmentation in Circular-Scan Synthetic-Aperture-Sonar Images using Semi-Supervised Convolutional Encoder-Decoders
Paper and Code
Jan 10, 2021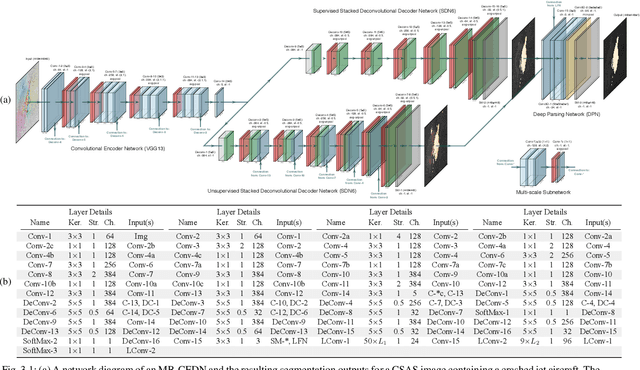
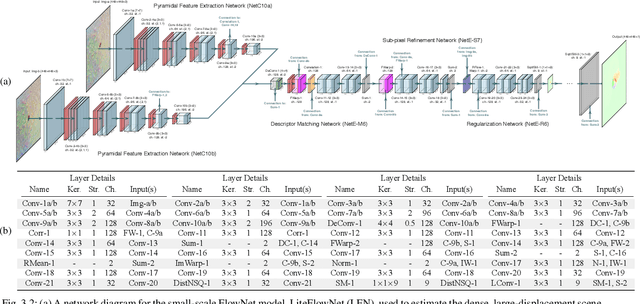
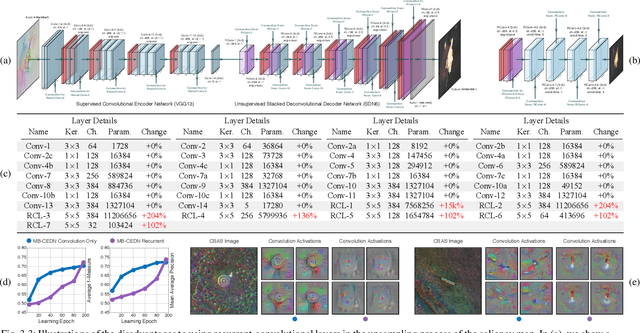
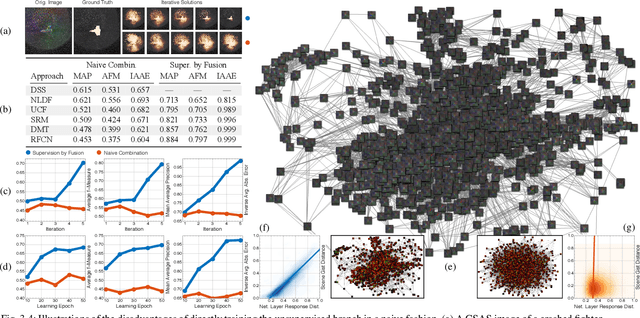
We propose a saliency-based, multi-target detection and segmentation framework for multi-aspect, semi-coherent imagery formed from circular-scan, synthetic-aperture sonar (CSAS). Our framework relies on a multi-branch, convolutional encoder-decoder network (MB-CEDN). The encoder portion extracts features from one or more CSAS images of the targets. These features are then split off and fed into multiple decoders that perform pixel-level classification on the extracted features to roughly mask the target in an unsupervised-trained manner and detect foreground and background pixels in a supervised-trained manner. Each of these target-detection estimates provide different perspectives as to what constitute a target. These opinions are cascaded into a deep-parsing network to model contextual and spatial constraints that help isolate targets better than either solution estimate alone. We evaluate our framework using real-world CSAS data with five broad target classes. Since we are the first to consider both CSAS target detection and segmentation, we adapt existing image and video-processing network topologies from the literature for comparative purposes. We show that our framework outperforms supervised deep networks. It greatly outperforms state-of-the-art unsupervised approaches for diverse target and seafloor types.