 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Semantic Segmentation of Circular-Scan, Synthetic-Aperture-Sonar Imagery
Jan 20, 2024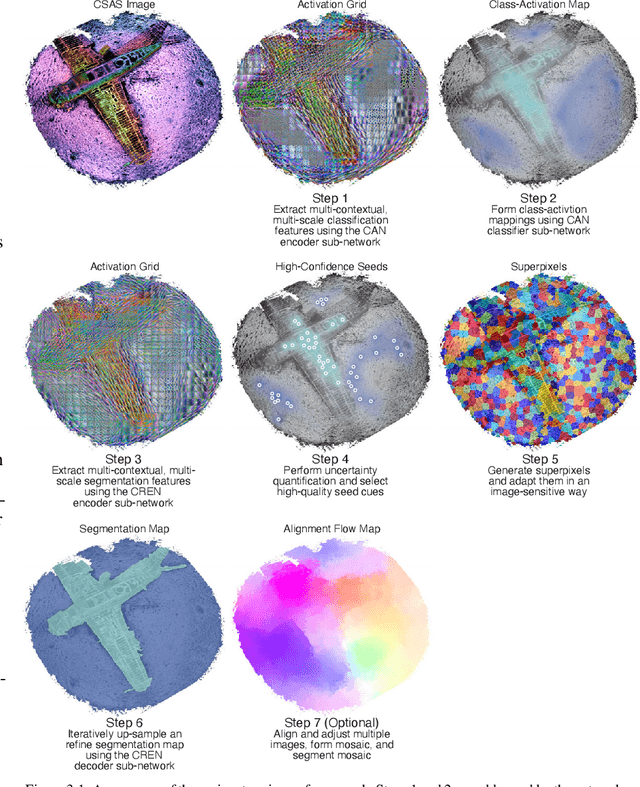
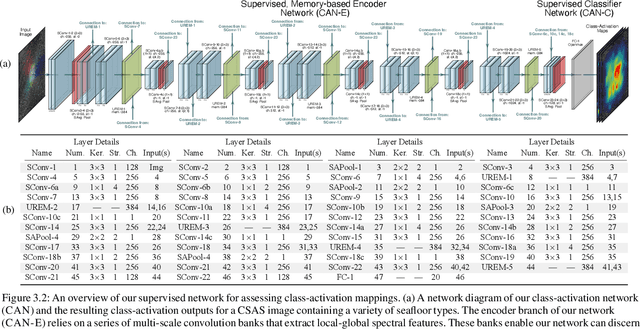
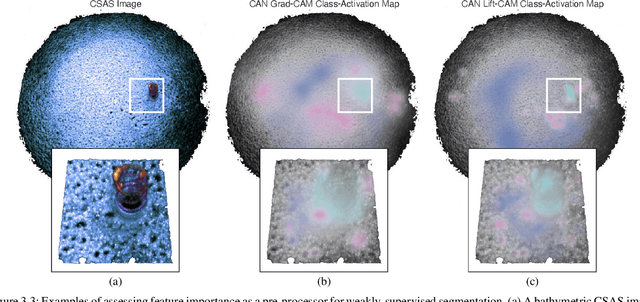
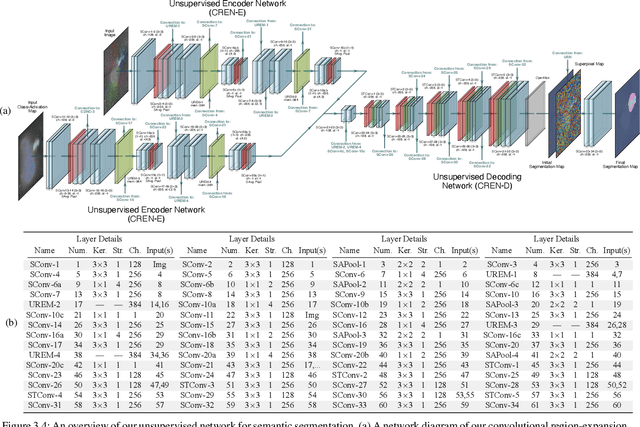
We propose a weakly-supervised framework for the semantic segmentation of circular-scan synthetic-aperture-sonar (CSAS) imagery. The first part of our framework is trained in a supervised manner, on image-level labels, to uncover a set of semi-sparse, spatially-discriminative regions in each image. The classification uncertainty of each region is then evaluated. Those areas with the lowest uncertainties are then chosen to be weakly labeled segmentation seeds, at the pixel level, for the second part of the framework. Each of the seed extents are progressively resized according to an unsupervised, information-theoretic loss with structured-prediction regularizers. This reshaping process uses multi-scale, adaptively-weighted features to delineate class-specific transitions in local image content. Content-addressable memories are inserted at various parts of our framework so that it can leverage features from previously seen images to improve segmentation performance for related images. We evaluate our weakly-supervised framework using real-world CSAS imagery that contains over ten seafloor classes and ten target classes. We show that our framework performs comparably to nine fully-supervised deep networks. Our framework also outperforms eleven of the best weakly-supervised deep networks. We achieve state-of-the-art performance when pre-training on natural imagery. The average absolute performance gap to the next-best weakly-supervised network is well over ten percent for both natural imagery and sonar imagery. This gap is found to be statistically significant.
Target Detection and Segmentation in Circular-Scan Synthetic-Aperture-Sonar Images using Semi-Supervised Convolutional Encoder-Decoders
Jan 10, 2021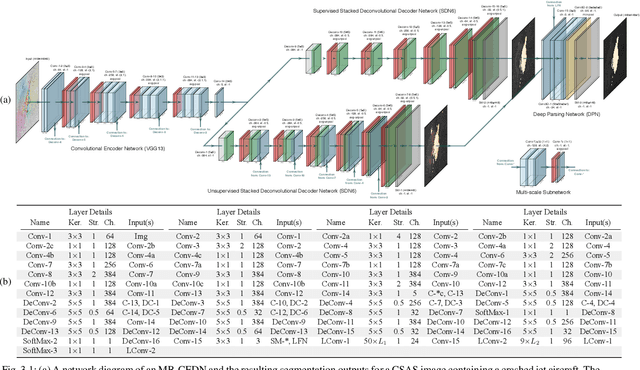
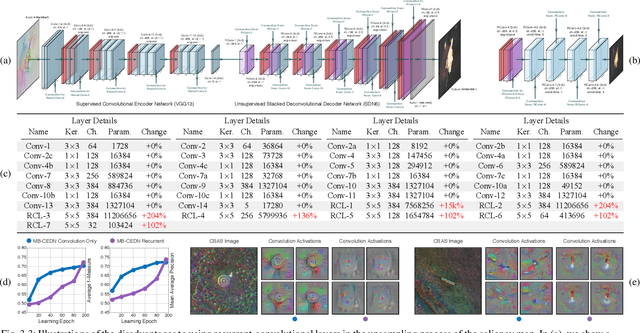
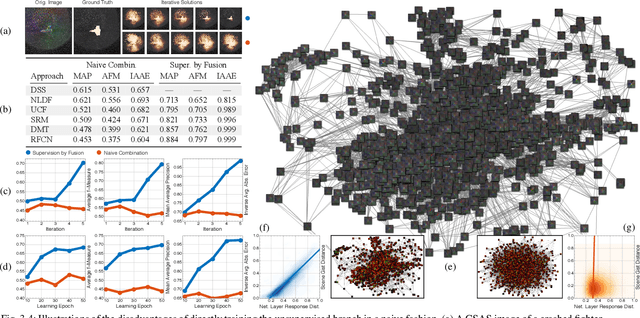
We propose a saliency-based, multi-target detection and segmentation framework for multi-aspect, semi-coherent imagery formed from circular-scan, synthetic-aperture sonar (CSAS). Our framework relies on a multi-branch, convolutional encoder-decoder network (MB-CEDN). The encoder portion extracts features from one or more CSAS images of the targets. These features are then split off and fed into multiple decoders that perform pixel-level classification on the extracted features to roughly mask the target in an unsupervised-trained manner and detect foreground and background pixels in a supervised-trained manner. Each of these target-detection estimates provide different perspectives as to what constitute a target. These opinions are cascaded into a deep-parsing network to model contextual and spatial constraints that help isolate targets better than either solution estimate alone. We evaluate our framework using real-world CSAS data with five broad target classes. Since we are the first to consider both CSAS target detection and segmentation, we adapt existing image and video-processing network topologies from the literature for comparative purposes. We show that our framework outperforms supervised deep networks. It greatly outperforms state-of-the-art unsupervised approaches for diverse target and seafloor types.