 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Motion Primitives for Simplifying Action Search in Reinforcement Learning
Feb 24, 2021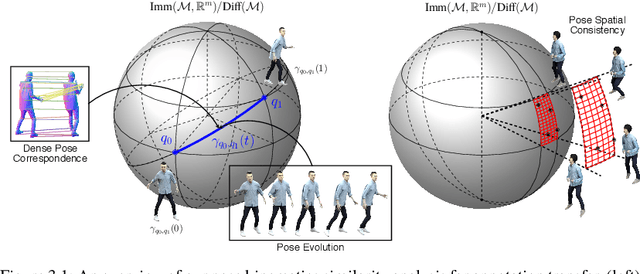
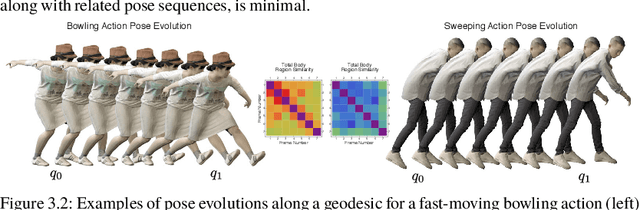
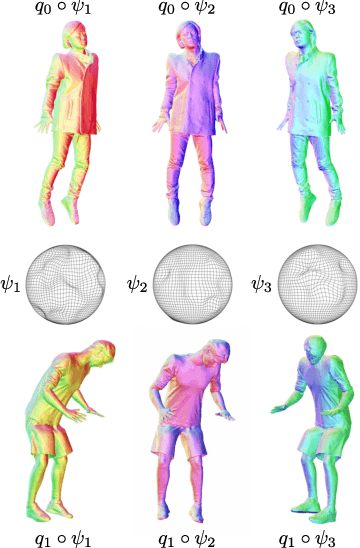
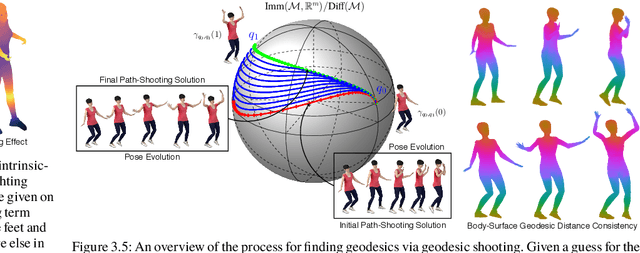
Reinforcement learning in large-scale environments is challenging due to the many possible actions that can be taken in specific situations. We have previously developed a means of constraining, and hence speeding up, the search process through the use of motion primitives; motion primitives are sequences of pre-specified actions taken across a state series. As a byproduct of this work, we have found that if the motion primitives' motions and actions are labeled, then the search can be sped up further. Since motion primitives may initially lack such details, we propose a theoretically viewpoint-insensitive and speed-insensitive means of automatically annotating the underlying motions and actions. We do this through a differential-geometric, spatio-temporal kinematics descriptor, which analyzes how the poses of entities in two motion sequences change over time. We use this descriptor in conjunction with a weighted-nearest-neighbor classifier to label the primitives using a limited set of training examples. In our experiments, we achieve high motion and action annotation rates for human-action-derived primitives with as few as one training sample. We also demonstrate that reinforcement learning using accurately labeled trajectories leads to high-performing policies more quickly than standard reinforcement learning techniques. This is partly because motion primitives encode prior domain knowledge and preempt the need to re-discover that knowledge during training. It is also because agents can leverage the labels to systematically ignore action classes that do not facilitate task objectives, thereby reducing the action space.