 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiNet: A Mobile Binary Network for Image Classification
Paper and Code
Jul 31, 2019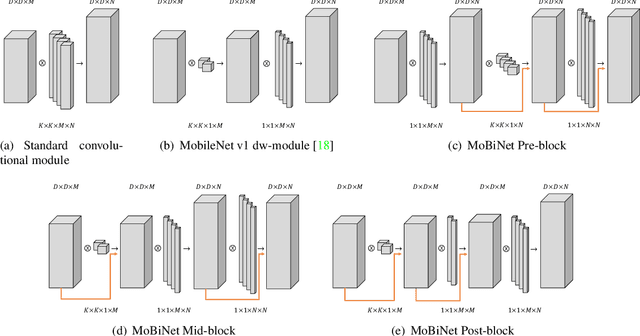

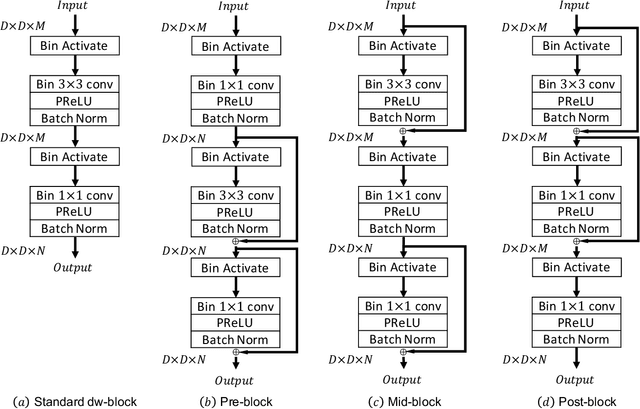
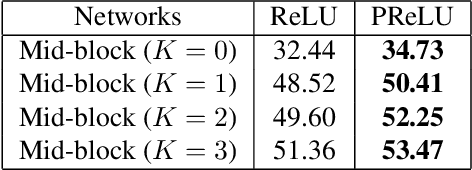
MobileNet and Binary Neural Networks are two among the most widely used techniques to construct deep learning models for performing a variety of tasks on mobile and embedded platforms.In this paper, we present a simple yet efficient scheme to exploit MobileNet binarization at activation function and model weights. However, training a binary network from scratch with separable depth-wise and point-wise convolutions in case of MobileNet is not trivial and prone to divergence. To tackle this training issue, we propose a novel neural network architecture, namely MoBiNet - Mobile Binary Network in which skip connections are manipulated to prevent information loss and vanishing gradient, thus facilitate the training process. More importantly, while existing binary neural networks often make use of cumbersome backbones such as Alex-Net, ResNet, VGG-16 with float-type pre-trained weights initialization, our MoBiNet focuses on binarizing the already-compressed neural networks like MobileNet without the need of a pre-trained model to start with. Therefore, our proposal results in an effectively small model while keeping the accuracy comparable to existing ones. Experiments on ImageNet dataset show the potential of the MoBiNet as it achieves 54.40% top-1 accuracy and dramatically reduces the computational cost with binary operators.