 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Laurel: Generating Dafny Assertions Using Large Language Models
May 27, 2024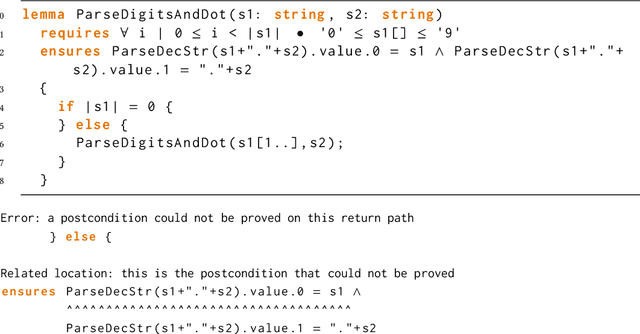

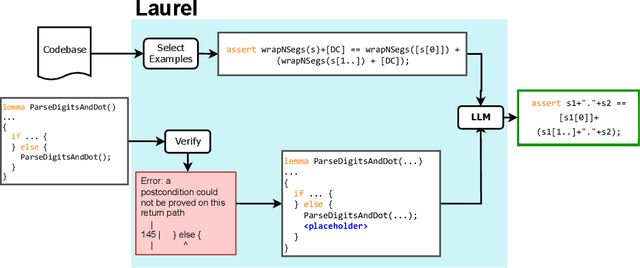

Dafny is a popular verification language, which automates proofs by outsourcing them to an SMT solver. This automation is not perfect, however, and the solver often requires guidance in the form of helper assertions creating a burden for the proof engineer. In this paper, we propose Laurel, a tool that uses large language models (LLMs) to automatically generate helper assertions for Dafny programs. To improve the success rate of LLMs in this task, we design two domain-specific prompting techniques. First, we help the LLM determine the location of the missing assertion by analyzing the verifier's error message and inserting an assertion placeholder at that location. Second, we provide the LLM with example assertions from the same codebase, which we select based on a new lemma similarity metric. We evaluate our techniques on a dataset of helper assertions we extracted from three real-world Dafny codebases. Our evaluation shows that Laurel is able to generate over 50% of the required helper assertions given only a few attempts, making LLMs a usable and affordable tool to further automate practical program verification.