 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Pass Document Scanning for Question Answering
Paper and Code
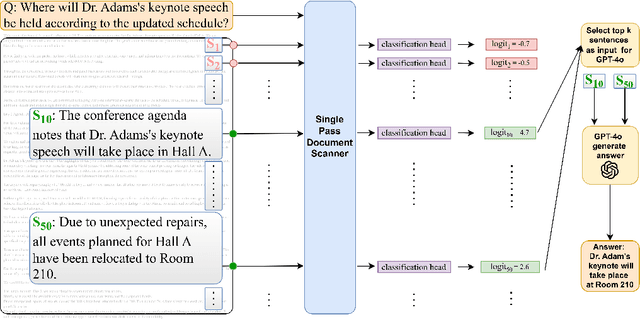
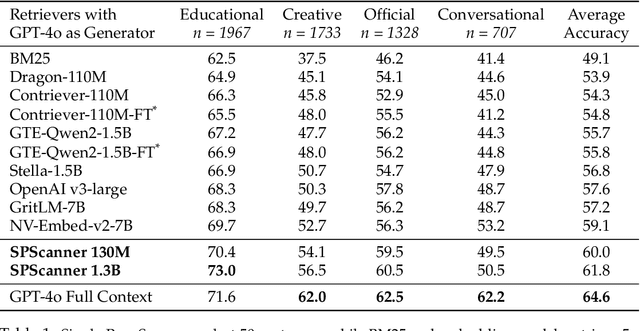
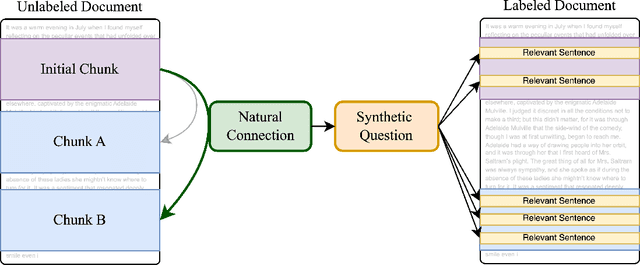
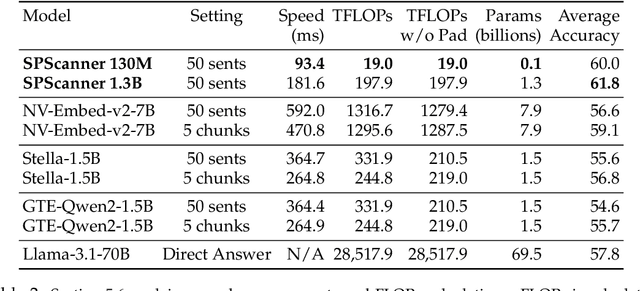
Handling extremely large documents for question answering is challenging: chunk-based embedding methods often lose track of important global context, while full-context transformers can be prohibitively expensive for hundreds of thousands of tokens. We propose a single-pass document scanning approach that processes the entire text in linear time, preserving global coherence while deciding which sentences are most relevant to the query. On 41 QA benchmarks, our single-pass scanner consistently outperforms chunk-based embedding methods and competes with large language models at a fraction of the computational cost. By conditioning on the entire preceding context without chunk breaks, the method preserves global coherence, which is especially important for long documents. Overall, single-pass document scanning offers a simple solution for question answering over massive text. All code, datasets, and model checkpoints are available at https://github.com/MambaRetriever/MambaRetriever