 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Shot In-Context Learning in Multimodal Foundation Models
May 16, 2024
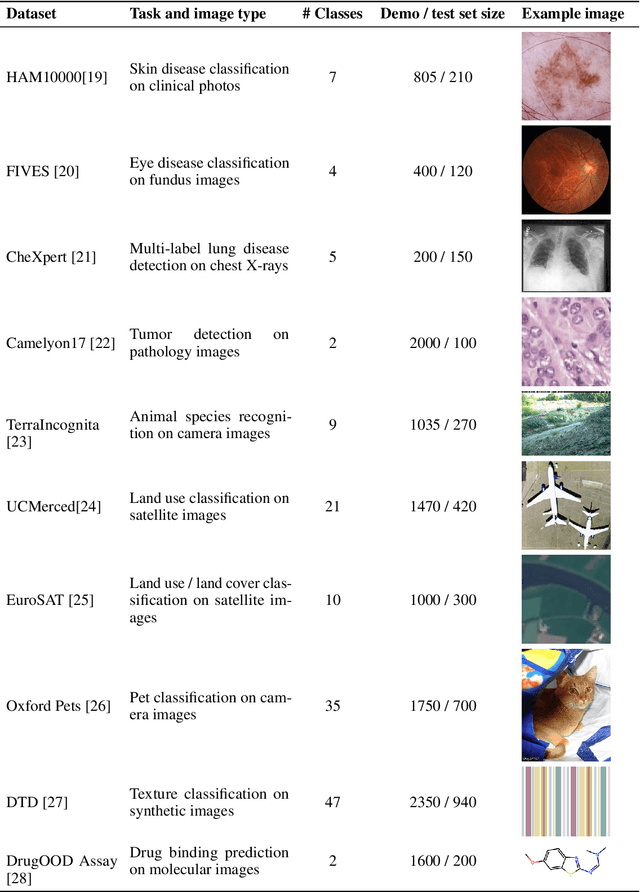
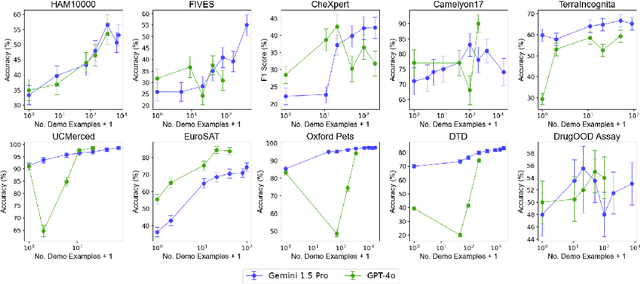
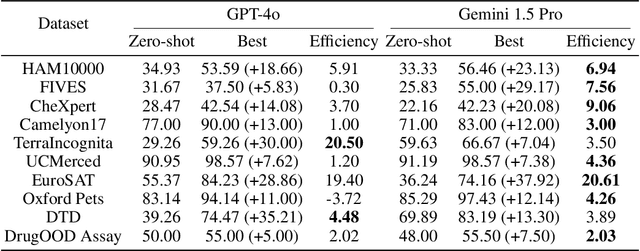
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
CloudTracks: A Dataset for Localizing Ship Tracks in Satellite Images of Clouds
Jan 25, 2024Clouds play a significant role in global temperature regulation through their effect on planetary albedo. Anthropogenic emissions of aerosols can alter the albedo of clouds, but the extent of this effect, and its consequent impact on temperature change, remains uncertain. Human-induced clouds caused by ship aerosol emissions, commonly referred to as ship tracks, provide visible manifestations of this effect distinct from adjacent cloud regions and therefore serve as a useful sandbox to study human-induced clouds. However, the lack of large-scale ship track data makes it difficult to deduce their general effects on cloud formation. Towards developing automated approaches to localize ship tracks at scale, we present CloudTracks, a dataset containing 3,560 satellite images labeled with more than 12,000 ship track instance annotations. We train semantic segmentation and instance segmentation model baselines on our dataset and find that our best model substantially outperforms previous state-of-the-art for ship track localization (61.29 vs. 48.65 IoU). We also find that the best instance segmentation model is able to identify the number of ship tracks in each image more accurately than the previous state-of-the-art (1.64 vs. 4.99 MAE). However, we identify cases where the best model struggles to accurately localize and count ship tracks, so we believe CloudTracks will stimulate novel machine learning approaches to better detect elongated and overlapping features in satellite images. We release our dataset openly at {zenodo.org/records/10042922}.