 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Shot In-Context Learning in Multimodal Foundation Models
May 16, 2024
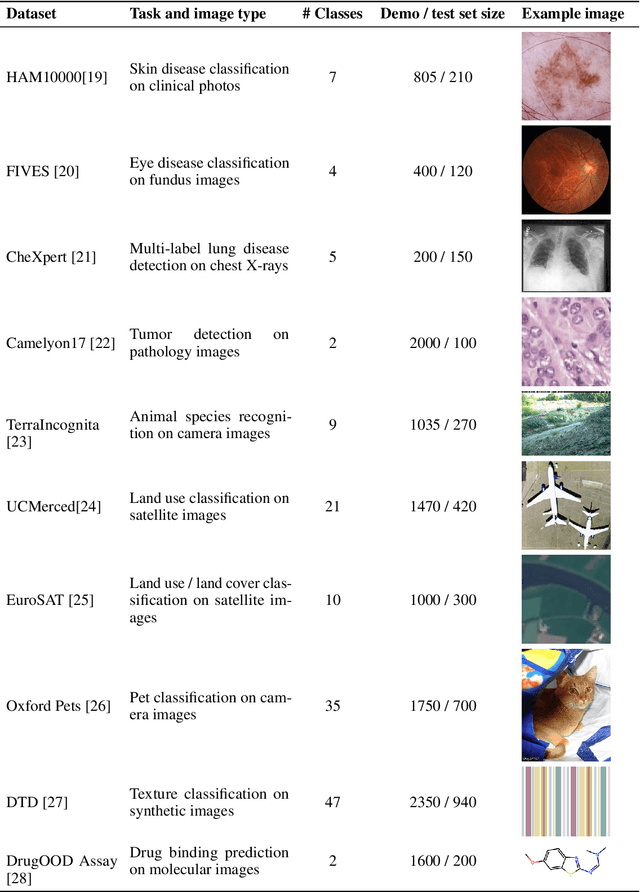
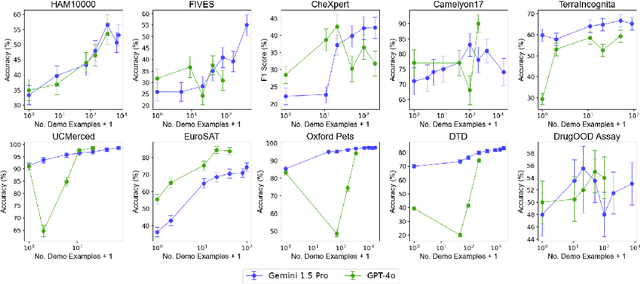
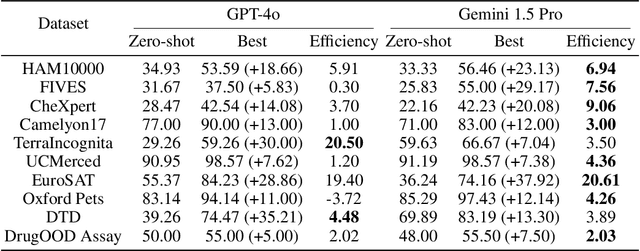
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
Weakly-semi-supervised object detection in remotely sensed imagery
Nov 29, 2023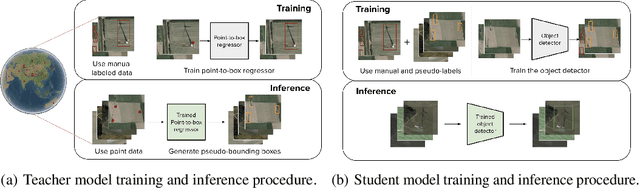
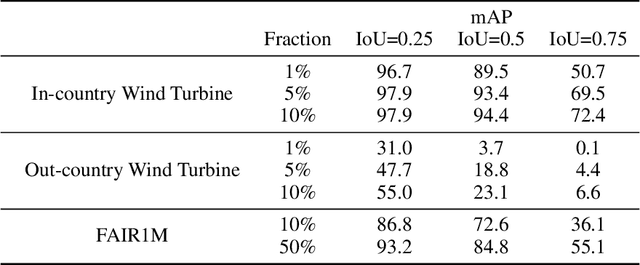
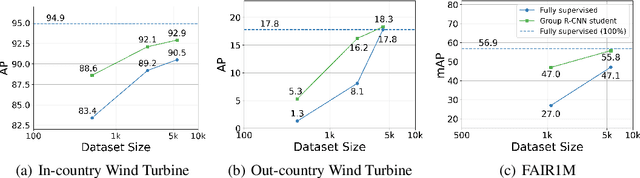

Deep learning for detecting objects in remotely sensed imagery can enable new technologies for important applications including mitigating climate change. However, these models often require large datasets labeled with bounding box annotations which are expensive to curate, prohibiting the development of models for new tasks and geographies. To address this challenge, we develop weakly-semi-supervised object detection (WSSOD) models on remotely sensed imagery which can leverage a small amount of bounding boxes together with a large amount of point labels that are easy to acquire at scale in geospatial data. We train WSSOD models which use large amounts of point-labeled images with varying fractions of bounding box labeled images in FAIR1M and a wind turbine detection dataset, and demonstrate that they substantially outperform fully supervised models trained with the same amount of bounding box labeled images on both datasets. Furthermore, we find that the WSSOD models trained with 2-10x fewer bounding box labeled images can perform similarly to or outperform fully supervised models trained on the full set of bounding-box labeled images. We believe that the approach can be extended to other remote sensing tasks to reduce reliance on bounding box labels and increase development of models for impactful applications.