 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs RobustBench/AutoAttack a suitable Benchmark for Adversarial Robustness?
Paper and Code
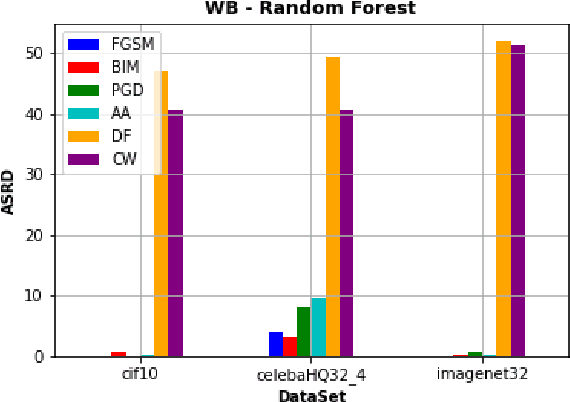
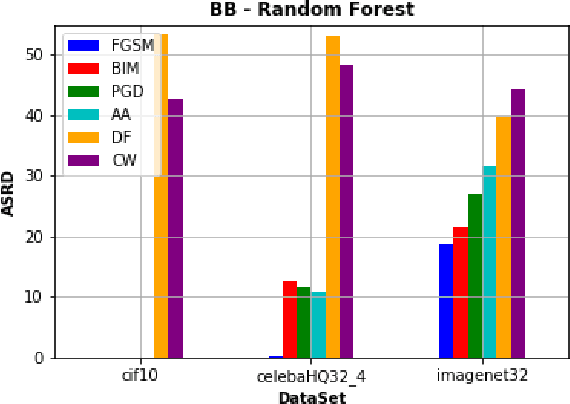
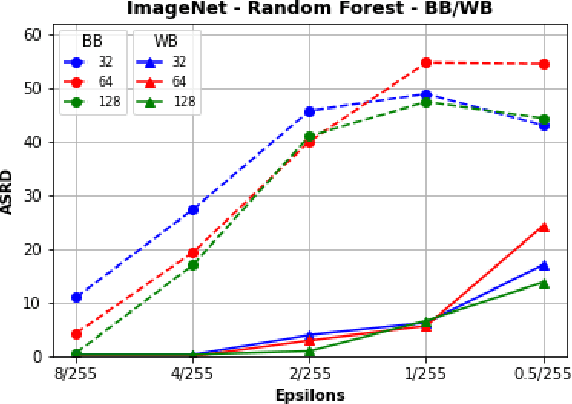
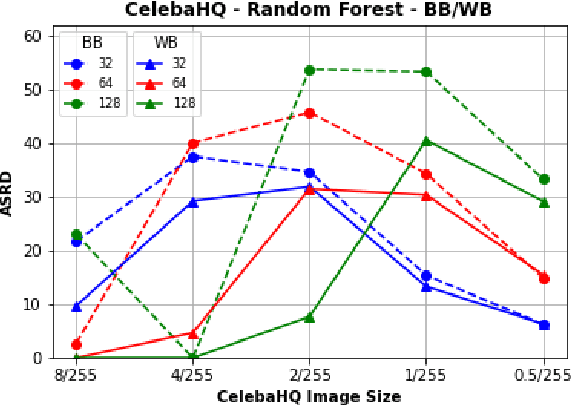
Recently, RobustBench (Croce et al. 2020) has become a widely recognized benchmark for the adversarial robustness of image classification networks. In its most commonly reported sub-task, RobustBench evaluates and ranks the adversarial robustness of trained neural networks on CIFAR10 under AutoAttack (Croce and Hein 2020b) with l-inf perturbations limited to eps = 8/255. With leading scores of the currently best performing models of around 60% of the baseline, it is fair to characterize this benchmark to be quite challenging. Despite its general acceptance in recent literature, we aim to foster discussion about the suitability of RobustBench as a key indicator for robustness which could be generalized to practical applications. Our line of argumentation against this is two-fold and supported by excessive experiments presented in this paper: We argue that I) the alternation of data by AutoAttack with l-inf, eps = 8/255 is unrealistically strong, resulting in close to perfect detection rates of adversarial samples even by simple detection algorithms and human observers. We also show that other attack methods are much harder to detect while achieving similar success rates. II) That results on low-resolution data sets like CIFAR10 do not generalize well to higher resolution images as gradient-based attacks appear to become even more detectable with increasing resolutions.