 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode Injection Link Stealing Attack
Jul 25, 2023
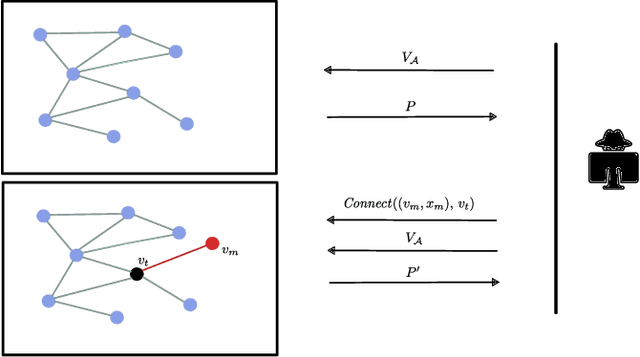
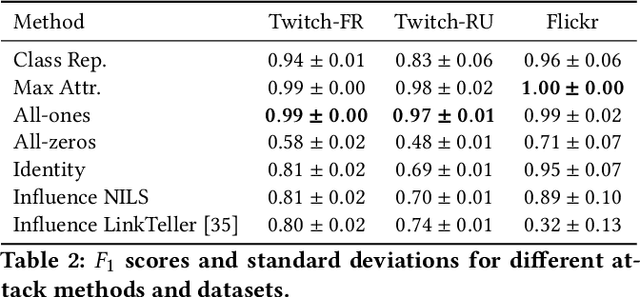
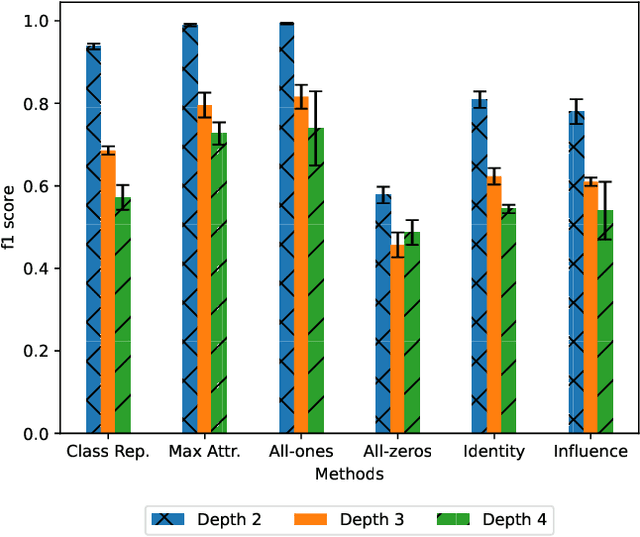
In this paper, we present a stealthy and effective attack that exposes privacy vulnerabilities in Graph Neural Networks (GNNs) by inferring private links within graph-structured data. Focusing on the inductive setting where new nodes join the graph and an API is used to query predictions, we investigate the potential leakage of private edge information. We also propose methods to preserve privacy while maintaining model utility. Our attack demonstrates superior performance in inferring the links compared to the state of the art. Furthermore, we examine the application of differential privacy (DP) mechanisms to mitigate the impact of our proposed attack, we analyze the trade-off between privacy preservation and model utility. Our work highlights the privacy vulnerabilities inherent in GNNs, underscoring the importance of developing robust privacy-preserving mechanisms for their application.
On the privacy-utility trade-off in differentially private hierarchical text classification
Mar 04, 2021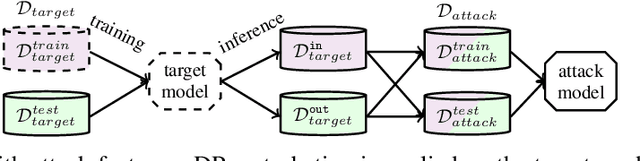



Hierarchical models for text classification can leak sensitive or confidential training data information to adversaries due to training data memorization. Using differential privacy during model training can mitigate leakage attacks against trained models by perturbing the training optimizer. However, for hierarchical text classification a multiplicity of model architectures is available and it is unclear whether some architectures yield a better trade-off between remaining model accuracy and model leakage under differentially private training perturbation than others. We use a white-box membership inference attack to assess the information leakage of three widely used neural network architectures for hierarchical text classification under differential privacy. We show that relatively weak differential privacy guarantees already suffice to completely mitigate the membership inference attack, thus resulting only in a moderate decrease in utility. More specifically, for large datasets with long texts we observed transformer-based models to achieve an overall favorable privacy-utility trade-off, while for smaller datasets with shorter texts CNNs are preferable.