 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the privacy-utility trade-off in differentially private hierarchical text classification
Mar 04, 2021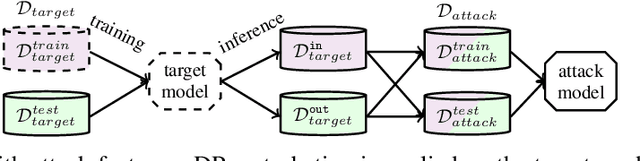



Hierarchical models for text classification can leak sensitive or confidential training data information to adversaries due to training data memorization. Using differential privacy during model training can mitigate leakage attacks against trained models by perturbing the training optimizer. However, for hierarchical text classification a multiplicity of model architectures is available and it is unclear whether some architectures yield a better trade-off between remaining model accuracy and model leakage under differentially private training perturbation than others. We use a white-box membership inference attack to assess the information leakage of three widely used neural network architectures for hierarchical text classification under differential privacy. We show that relatively weak differential privacy guarantees already suffice to completely mitigate the membership inference attack, thus resulting only in a moderate decrease in utility. More specifically, for large datasets with long texts we observed transformer-based models to achieve an overall favorable privacy-utility trade-off, while for smaller datasets with shorter texts CNNs are preferable.