 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-based Agentic Large Language Model Framework for Harmonized Tariff Schedule Code Classification
Jun 15, 2026Accurate Harmonized Tariff Schedule (HTS) code classification is essential for customs clearance, duty assessment, trade statistics, and regulatory compliance in maritime logistics. However, exact HTS classification remains challenging because product descriptions are often short, incomplete, or ambiguous, while correct classification depends on hierarchical tariff structures, legal notes, and jurisdiction-specific rules. This paper proposes an agentic large language model (LLM) framework for Canadian 10-digit HTS code classification in smart-port and maritime logistics environments. The framework integrates multi-agent information retrieval, semantic retrieval over official tariff documents, evidence-grounded reasoning, consensus-based validation, element-wise voting across hierarchical code components, confidence estimation, and human-in-the-loop escalation. We evaluate the framework on a private dataset of 3,300 domain-expert-labeled product records collected from logistics and delivery contexts. Experimental results show that exact 10-digit classification remains difficult even for advanced LLMs, with performance decreasing from coarse chapter-level prediction to fine-grained tariff and statistical suffix assignment. These findings demonstrate the need for evidence-grounded, uncertainty-aware, and human-centered classification workflows rather than fully autonomous single-step prediction. The proposed framework supports more interpretable, accountable, and compliance-oriented HTS classification for maritime logistics and smart-port operations. Our code is available at https://github.com/Analytics-Everywhere-Lab/hts.
Multi-Dimensional Model Integrity and Responsibility Assessment Index and Scoring Framework
May 14, 2026Artificial intelligence in high-stakes tabular domains cannot be evaluated by predictive performance alone, yet current practice still assesses explainability, fairness, robustness, privacy, and sustainability mostly in isolation. We propose the Model Integrity and Responsibility Assessment Index (MIRAI), a unified evaluation framework that measures tabular models across these five dimensions under a controlled comparison setting and aggregates them into a single score. MIRAI combines established metrics through normalized and direction-aligned dimension scores, which enables direct comparison across models with different architectural and computational profiles. Experiments on healthcare, financial, and socioeconomic datasets show that higher predictive performance does not necessarily imply better overall integrity and responsibility. In several cases, simpler models achieve a stronger cross-dimensional balance than more complex deep tabular architectures. MIRAI provides a compact and practical basis for responsible model selection in regulated settings.
Contestable Multi-Agent Debate with Arena-based Argumentative Computation for Multimedia Verification
May 14, 2026Multimedia verification requires not only accurate conclusions but also transparent and contestable reasoning. We propose a contestable multi-agent framework that integrates multimodal large language models, external verification tools, and arena-based quantitative bipolar argumentation (A-QBAF) as a submission to the ICMR 2026 Grand Challenge on Multimedia Verification. Our method decomposes each case into claim-centered sections, retrieves targeted evidence, and converts evidence into structured support and attack arguments with provenance and strength scores. These arguments are resolved through small local argument graphs with selective clash resolution and uncertainty-aware escalation. The resulting system generates section-wise verification reports that are transparent, editable, and computationally practical for real-world multimedia verification. Our implementation is public at: https://github.com/Analytics-Everywhere-Lab/MV2026_the_liems.
Position: Multi-Agent Algorithmic Care Systems Demand Contestability for Trustworthy AI
Mar 21, 2026Multi-agent systems (MAS) are increasingly used in healthcare to support complex decision-making through collaboration among specialized agents. Because these systems act as collective decision-makers, they raise challenges for trust, accountability, and human oversight. Existing approaches to trustworthy AI largely rely on explainability, but explainability alone is insufficient in multi-agent settings, as it does not enable care partners to challenge or correct system outputs. To address this limitation, Contestable AI (CAI) characterizes systems that support effective human challenge throughout the decision-making lifecycle by providing transparency, structured opportunities for intervention, and mechanisms for review, correction, or override. This position paper argues that contestability is a necessary design requirement for trustworthy multi-agent algorithmic care systems. We identify key limitations in current MAS and Explainable AI (XAI) research and present a human-in-the-loop framework that integrates structured argumentation and role-based contestation to preserve human agency, clinical responsibility, and trust in high-stakes care contexts.
Adaptive Collaboration of Arena-Based Argumentative LLMs for Explainable and Contestable Legal Reasoning
Feb 21, 2026Legal reasoning requires not only high accuracy but also the ability to justify decisions through verifiable and contestable arguments. However, existing Large Language Model (LLM) approaches, such as Chain-of-Thought (CoT) and Retrieval-Augmented Generation (RAG), often produce unstructured explanations that lack a formal mechanism for verification or user intervention. To address this limitation, we propose Adaptive Collaboration of Argumentative LLMs (ACAL), a neuro-symbolic framework that integrates adaptive multi-agent collaboration with an Arena-based Quantitative Bipolar Argumentation Framework (A-QBAF). ACAL dynamically deploys expert agent teams to construct arguments, employs a clash resolution mechanism to adjudicate conflicting claims, and utilizes uncertainty-aware escalation for borderline cases. Crucially, our framework supports a Human-in-the-Loop (HITL) contestability workflow, enabling users to directly audit and modify the underlying reasoning graph to influence the final judgment. Empirical evaluations on the LegalBench benchmark demonstrate that ACAL outperforms strong baselines across Gemini-2.5-Flash-Lite and Gemini-2.5-Flash architectures, effectively balancing efficient predictive performance with structured transparency and contestability. Our implementation is available at: https://github.com/loc110504/ACAL.
XEdgeAI: A Human-centered Industrial Inspection Framework with Data-centric Explainable Edge AI Approach
Jul 16, 2024



Recent advancements in deep learning have significantly improved visual quality inspection and predictive maintenance within industrial settings. However, deploying these technologies on low-resource edge devices poses substantial challenges due to their high computational demands and the inherent complexity of Explainable AI (XAI) methods. This paper addresses these challenges by introducing a novel XAI-integrated Visual Quality Inspection framework that optimizes the deployment of semantic segmentation models on low-resource edge devices. Our framework incorporates XAI and the Large Vision Language Model to deliver human-centered interpretability through visual and textual explanations to end-users. This is crucial for end-user trust and model interpretability. We outline a comprehensive methodology consisting of six fundamental modules: base model fine-tuning, XAI-based explanation generation, evaluation of XAI approaches, XAI-guided data augmentation, development of an edge-compatible model, and the generation of understandable visual and textual explanations. Through XAI-guided data augmentation, the enhanced model incorporating domain expert knowledge with visual and textual explanations is successfully deployed on mobile devices to support end-users in real-world scenarios. Experimental results showcase the effectiveness of the proposed framework, with the mobile model achieving competitive accuracy while significantly reducing model size. This approach paves the way for the broader adoption of reliable and interpretable AI tools in critical industrial applications, where decisions must be both rapid and justifiable.
Efficient and Concise Explanations for Object Detection with Gaussian-Class Activation Mapping Explainer
Apr 20, 2024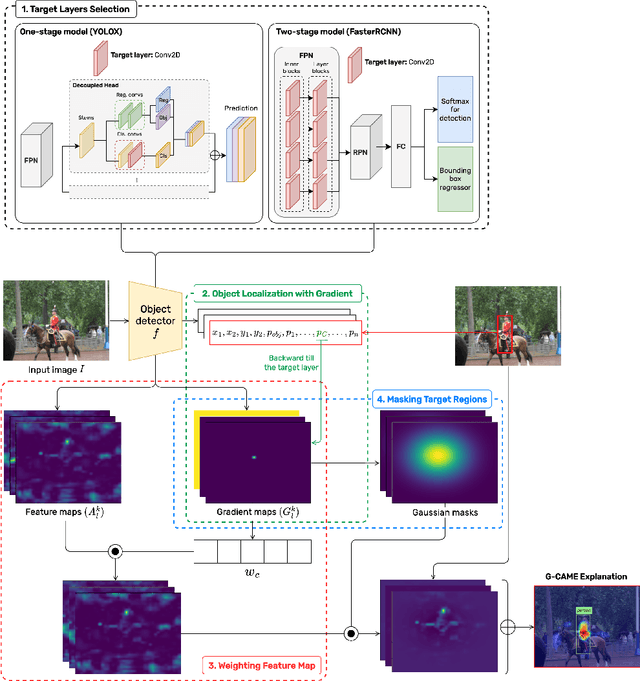

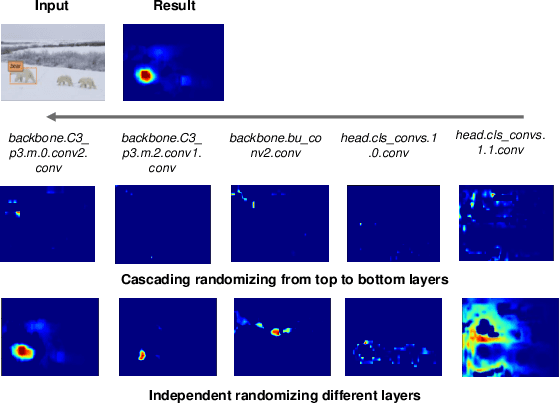
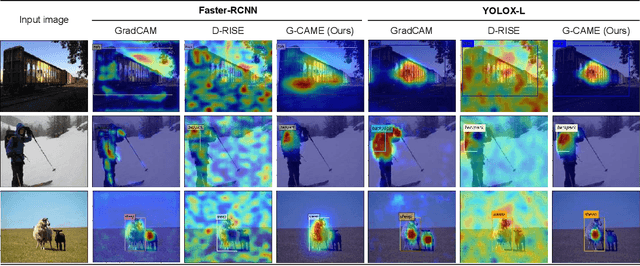
To address the challenges of providing quick and plausible explanations in Explainable AI (XAI) for object detection models, we introduce the Gaussian Class Activation Mapping Explainer (G-CAME). Our method efficiently generates concise saliency maps by utilizing activation maps from selected layers and applying a Gaussian kernel to emphasize critical image regions for the predicted object. Compared with other Region-based approaches, G-CAME significantly reduces explanation time to 0.5 seconds without compromising the quality. Our evaluation of G-CAME, using Faster-RCNN and YOLOX on the MS-COCO 2017 dataset, demonstrates its ability to offer highly plausible and faithful explanations, especially in reducing the bias on tiny object detection.
LangXAI: Integrating Large Vision Models for Generating Textual Explanations to Enhance Explainability in Visual Perception Tasks
Feb 19, 2024



LangXAI is a framework that integrates Explainable Artificial Intelligence (XAI) with advanced vision models to generate textual explanations for visual recognition tasks. Despite XAI advancements, an understanding gap persists for end-users with limited domain knowledge in artificial intelligence and computer vision. LangXAI addresses this by furnishing text-based explanations for classification, object detection, and semantic segmentation model outputs to end-users. Preliminary results demonstrate LangXAI's enhanced plausibility, with high BERTScore across tasks, fostering a more transparent and reliable AI framework on vision tasks for end-users.
Examining Monitoring System: Detecting Abnormal Behavior In Online Examinations
Feb 19, 2024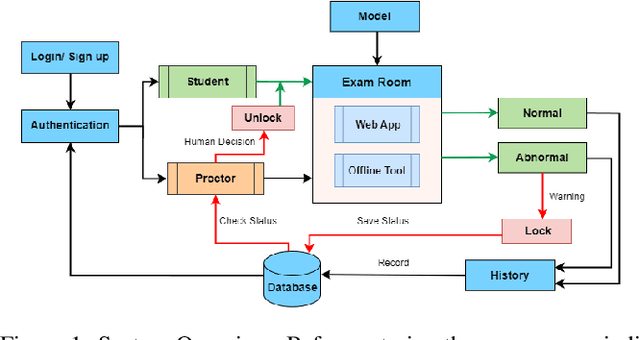
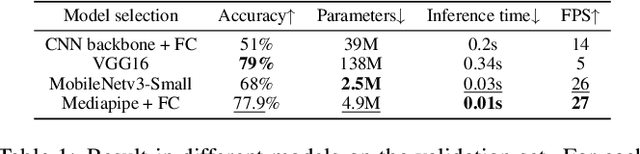
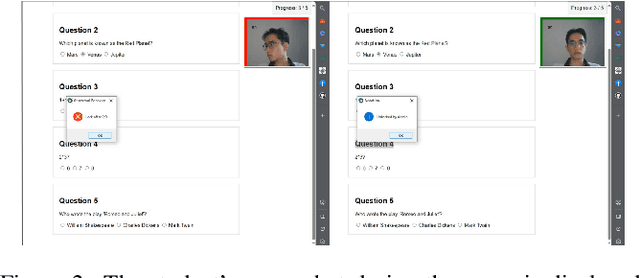
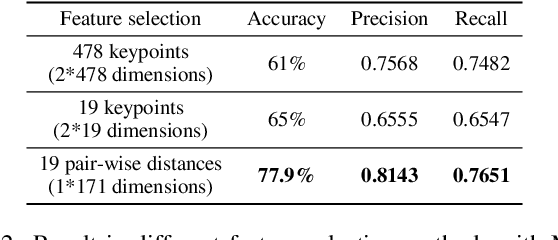
Cheating in online exams has become a prevalent issue over the past decade, especially during the COVID-19 pandemic. To address this issue of academic dishonesty, our "Exam Monitoring System: Detecting Abnormal Behavior in Online Examinations" is designed to assist proctors in identifying unusual student behavior. Our system demonstrates high accuracy and speed in detecting cheating in real-time scenarios, providing valuable information, and aiding proctors in decision-making. This article outlines our methodology and the effectiveness of our system in mitigating the widespread problem of cheating in online exams.
Enhancing the Fairness and Performance of Edge Cameras with Explainable AI
Jan 18, 2024
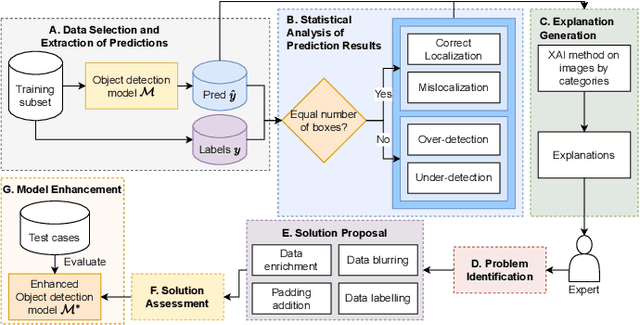
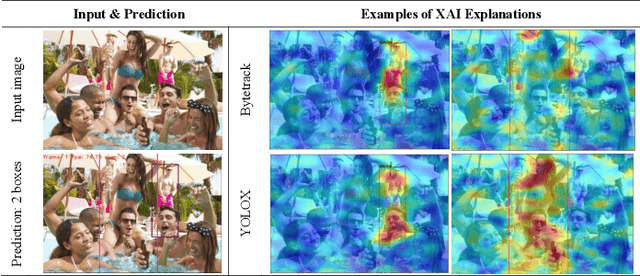

The rising use of Artificial Intelligence (AI) in human detection on Edge camera systems has led to accurate but complex models, challenging to interpret and debug. Our research presents a diagnostic method using Explainable AI (XAI) for model debugging, with expert-driven problem identification and solution creation. Validated on the Bytetrack model in a real-world office Edge network, we found the training dataset as the main bias source and suggested model augmentation as a solution. Our approach helps identify model biases, essential for achieving fair and trustworthy models.