 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary Ensemble Learning
Paper and Code
Nov 09, 2021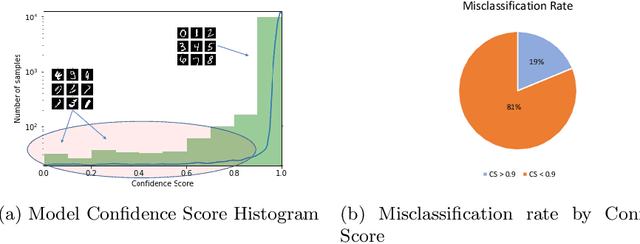
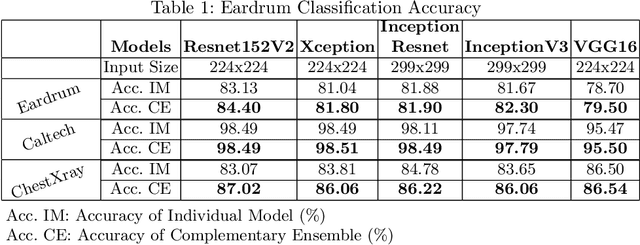

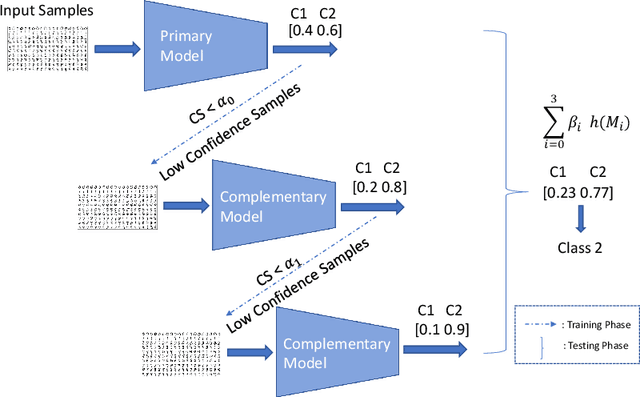
To achieve high performance of a machine learning (ML) task, a deep learning-based model must implicitly capture the entire distribution from data. Thus, it requires a huge amount of training samples, and data are expected to fully present the real distribution, especially for high dimensional data, e.g., images, videos. In practice, however, data are usually collected with a diversity of styles, and several of them have insufficient number of representatives. This might lead to uncertainty in models' prediction, and significantly reduce ML task performance. In this paper, we provide a comprehensive study on this problem by looking at model uncertainty. From this, we derive a simple but efficient technique to improve performance of state-of-the-art deep learning models. Specifically, we train auxiliary models which are able to complement state-of-the-art model uncertainty. As a result, by assembling these models, we can significantly improve the ML task performance for types of data mentioned earlier. While slightly improving ML classification accuracy on benchmark datasets (e.g., 0.2% on MNIST), our proposed method significantly improves on limited data (i.e., 1.3% on Eardrum and 3.5% on ChestXray).