 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSherlock: Towards Multi-scene Video Abnormal Event Extraction and Localization via a Global-local Spatial-sensitive LLM
Feb 26, 2025Prior studies on Video Anomaly Detection (VAD) mainly focus on detecting whether each video frame is abnormal or not in the video, which largely ignore the structured video semantic information (i.e., what, when, and where does the abnormal event happen). With this in mind, we propose a new chat-paradigm \textbf{M}ulti-scene Video Abnormal Event Extraction and Localization (M-VAE) task, aiming to extract the abnormal event quadruples (i.e., subject, event type, object, scene) and localize such event. Further, this paper believes that this new task faces two key challenges, i.e., global-local spatial modeling and global-local spatial balancing. To this end, this paper proposes a Global-local Spatial-sensitive Large Language Model (LLM) named Sherlock, i.e., acting like Sherlock Holmes to track down the criminal events, for this M-VAE task. Specifically, this model designs a Global-local Spatial-enhanced MoE (GSM) module and a Spatial Imbalance Regulator (SIR) to address the two challenges respectively. Extensive experiments on our M-VAE instruction dataset show the significant advantages of Sherlock over several advanced Video-LLMs. This justifies the importance of global-local spatial information for the M-VAE task and the effectiveness of Sherlock in capturing such information.
ChatASU: Evoking LLM's Reflexion to Truly Understand Aspect Sentiment in Dialogues
Mar 12, 2024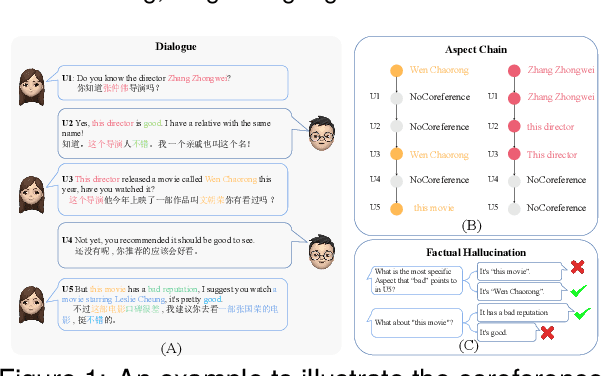
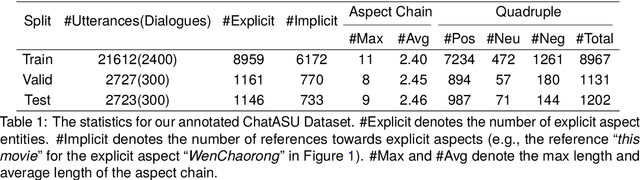
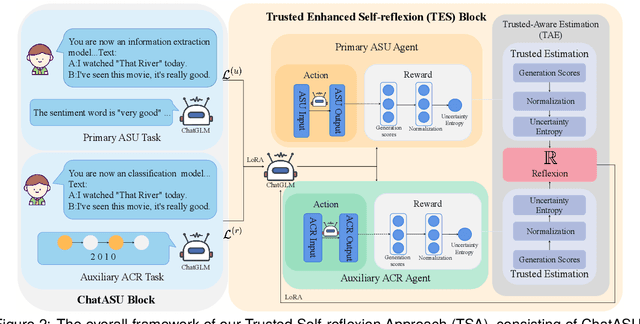

Aspect Sentiment Understanding (ASU) in interactive scenarios (e.g., Question-Answering and Dialogue) has attracted ever-more interest in recent years and achieved important progresses. However, existing studies on interactive ASU largely ignore the coreference issue for opinion targets (i.e., aspects), while this phenomenon is ubiquitous in interactive scenarios especially dialogues, limiting the ASU performance. Recently, large language models (LLMs) shows the powerful ability to integrate various NLP tasks with the chat paradigm. In this way, this paper proposes a new Chat-based Aspect Sentiment Understanding (ChatASU) task, aiming to explore LLMs' ability in understanding aspect sentiments in dialogue scenarios. Particularly, this ChatASU task introduces a sub-task, i.e., Aspect Chain Reasoning (ACR) task, to address the aspect coreference issue. On this basis, we propose a Trusted Self-reflexion Approach (TSA) with ChatGLM as backbone to ChatASU. Specifically, this TSA treats the ACR task as an auxiliary task to boost the performance of the primary ASU task, and further integrates trusted learning into reflexion mechanisms to alleviate the LLMs-intrinsic factual hallucination problem in TSA. Furthermore, a high-quality ChatASU dataset is annotated to evaluate TSA, and extensive experiments show that our proposed TSA can significantly outperform several state-of-the-art baselines, justifying the effectiveness of TSA to ChatASU and the importance of considering the coreference and hallucination issues in ChatASU.
TopicDiff: A Topic-enriched Diffusion Approach for Multimodal Conversational Emotion Detection
Mar 11, 2024Multimodal Conversational Emotion (MCE) detection, generally spanning across the acoustic, vision and language modalities, has attracted increasing interest in the multimedia community. Previous studies predominantly focus on learning contextual information in conversations with only a few considering the topic information in single language modality, while always neglecting the acoustic and vision topic information. On this basis, we propose a model-agnostic Topic-enriched Diffusion (TopicDiff) approach for capturing multimodal topic information in MCE tasks. Particularly, we integrate the diffusion model into neural topic model to alleviate the diversity deficiency problem of neural topic model in capturing topic information. Detailed evaluations demonstrate the significant improvements of TopicDiff over the state-of-the-art MCE baselines, justifying the importance of multimodal topic information to MCE and the effectiveness of TopicDiff in capturing such information. Furthermore, we observe an interesting finding that the topic information in acoustic and vision is more discriminative and robust compared to the language.
How to Understand "Support"? An Implicit-enhanced Causal Inference Approach for Weakly-supervised Phrase Grounding
Mar 04, 2024



Weakly-supervised Phrase Grounding (WPG) is an emerging task of inferring the fine-grained phrase-region matching, while merely leveraging the coarse-grained sentence-image pairs for training. However, existing studies on WPG largely ignore the implicit phrase-region matching relations, which are crucial for evaluating the capability of models in understanding the deep multimodal semantics. To this end, this paper proposes an Implicit-Enhanced Causal Inference (IECI) approach to address the challenges of modeling the implicit relations and highlighting them beyond the explicit. Specifically, this approach leverages both the intervention and counterfactual techniques to tackle the above two challenges respectively. Furthermore, a high-quality implicit-enhanced dataset is annotated to evaluate IECI and detailed evaluations show the great advantages of IECI over the state-of-the-art baselines. Particularly, we observe an interesting finding that IECI outperforms the advanced multimodal LLMs by a large margin on this implicit-enhanced dataset, which may facilitate more research to evaluate the multimodal LLMs in this direction.