 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous battery research: Principles of heuristic operando experimentation
Dec 29, 2025Unravelling the complex processes governing battery degradation is critical to the energy transition, yet the efficacy of operando characterisation is severely constrained by a lack of Reliability, Representativeness, and Reproducibility (the 3Rs). Current methods rely on bespoke hardware and passive, pre-programmed methodologies that are ill-equipped to capture stochastic failure events. Here, using the Rutherford Appleton Laboratory's multi-modal toolkit as a case study, we expose the systemic inability of conventional experiments to capture transient phenomena like dendrite initiation. To address this, we propose Heuristic Operando experiments: a framework where an AI pilot leverages physics-based digital twins to actively steer the beamline to predict and deterministically capture these rare events. Distinct from uncertainty-driven active learning, this proactive search anticipates failure precursors, redefining experimental efficiency via an entropy-based metric that prioritises scientific insight per photon, neutron, or muon. By focusing measurements only on mechanistically decisive moments, this framework simultaneously mitigates beam damage and drastically reduces data redundancy. When integrated with FAIR data principles, this approach serves as a blueprint for the trusted autonomous battery laboratories of the future.
No-regret incentive-compatible online learning under exact truthfulness with non-myopic experts
Feb 17, 2025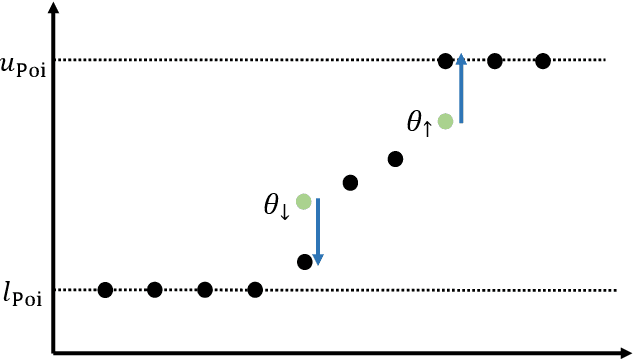
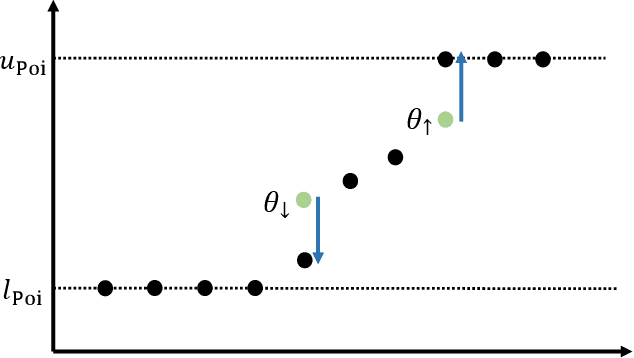
We study an online forecasting setting in which, over $T$ rounds, $N$ strategic experts each report a forecast to a mechanism, the mechanism selects one forecast, and then the outcome is revealed. In any given round, each expert has a belief about the outcome, but the expert wishes to select its report so as to maximize the total number of times it is selected. The goal of the mechanism is to obtain low belief regret: the difference between its cumulative loss (based on its selected forecasts) and the cumulative loss of the best expert in hindsight (as measured by the experts' beliefs). We consider exactly truthful mechanisms for non-myopic experts, meaning that truthfully reporting its belief strictly maximizes the expert's subjective probability of being selected in any future round. Even in the full-information setting, it is an open problem to obtain the first no-regret exactly truthful mechanism in this setting. We develop the first no-regret mechanism for this setting via an online extension of the Independent-Event Lotteries Forecasting Competition Mechanism (I-ELF). By viewing this online I-ELF as a novel instance of Follow the Perturbed Leader (FPL) with noise based on random walks with loss-dependent perturbations, we obtain $\tilde{O}(\sqrt{T N})$ regret. Our results are fueled by new tail bounds for Poisson binomial random variables that we develop. We extend our results to the bandit setting, where we give an exactly truthful mechanism obtaining $\tilde{O}(T^{2/3} N^{1/3})$ regret; this is the first no-regret result even among approximately truthful mechanisms.
On the price of exact truthfulness in incentive-compatible online learning with bandit feedback: A regret lower bound for WSU-UX
Apr 08, 2024In one view of the classical game of prediction with expert advice with binary outcomes, in each round, each expert maintains an adversarially chosen belief and honestly reports this belief. We consider a recently introduced, strategic variant of this problem with selfish (reputation-seeking) experts, where each expert strategically reports in order to maximize their expected future reputation based on their belief. In this work, our goal is to design an algorithm for the selfish experts problem that is incentive-compatible (IC, or \emph{truthful}), meaning each expert's best strategy is to report truthfully, while also ensuring the algorithm enjoys sublinear regret with respect to the expert with the best belief. Freeman et al. (2020) recently studied this problem in the full information and bandit settings and obtained truthful, no-regret algorithms by leveraging prior work on wagering mechanisms. While their results under full information match the minimax rate for the classical ("honest experts") problem, the best-known regret for their bandit algorithm WSU-UX is $O(T^{2/3})$, which does not match the minimax rate for the classical ("honest bandits") setting. It was unclear whether the higher regret was an artifact of their analysis or a limitation of WSU-UX. We show, via explicit construction of loss sequences, that the algorithm suffers a worst-case $\Omega(T^{2/3})$ lower bound. Left open is the possibility that a different IC algorithm obtains $O(\sqrt{T})$ regret. Yet, WSU-UX was a natural choice for such an algorithm owing to the limited design room for IC algorithms in this setting.
Best-Case Lower Bounds in Online Learning
Jun 23, 2021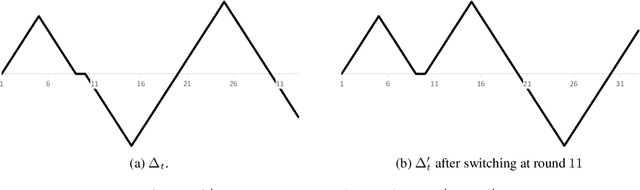
Much of the work in online learning focuses on the study of sublinear upper bounds on the regret. In this work, we initiate the study of best-case lower bounds in online convex optimization, wherein we bound the largest improvement an algorithm can obtain relative to the single best action in hindsight. This problem is motivated by the goal of better understanding the adaptivity of a learning algorithm. Another motivation comes from fairness: it is known that best-case lower bounds are instrumental in obtaining algorithms for decision-theoretic online learning (DTOL) that satisfy a notion of group fairness. Our contributions are a general method to provide best-case lower bounds in Follow The Regularized Leader (FTRL) algorithms with time-varying regularizers, which we use to show that best-case lower bounds are of the same order as existing upper regret bounds: this includes situations with a fixed learning rate, decreasing learning rates, timeless methods, and adaptive gradient methods. In stark contrast, we show that the linearized version of FTRL can attain negative linear regret. Finally, in DTOL with two experts and binary predictions, we fully characterize the best-case sequences, which provides a finer understanding of the best-case lower bounds.