 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADReview: Automatically Reviewing CAD Programs with Error Detection and Correction
May 28, 2025Computer-aided design (CAD) is crucial in prototyping 3D objects through geometric instructions (i.e., CAD programs). In practical design workflows, designers often engage in time-consuming reviews and refinements of these prototypes by comparing them with reference images. To bridge this gap, we introduce the CAD review task to automatically detect and correct potential errors, ensuring consistency between the constructed 3D objects and reference images. However, recent advanced multimodal large language models (MLLMs) struggle to recognize multiple geometric components and perform spatial geometric operations within the CAD program, leading to inaccurate reviews. In this paper, we propose the CAD program repairer (ReCAD) framework to effectively detect program errors and provide helpful feedback on error correction. Additionally, we create a dataset, CADReview, consisting of over 20K program-image pairs, with diverse errors for the CAD review task. Extensive experiments demonstrate that our ReCAD significantly outperforms existing MLLMs, which shows great potential in design applications.
Classic4Children: Adapting Chinese Literary Classics for Children with Large Language Model
Feb 03, 2025



Chinese literary classics hold significant cultural and educational value, offering deep insights into morality, history, and human nature. These works often include classical Chinese and complex narratives, making them difficult for children to read. To bridge this gap, we introduce a child-friendly literary adaptation (CLA) task to adapt the Chinese literary classic into engaging and accessible text for children. However, recent large language models (LLMs) overlook children's reading preferences (\ie, vivid character portrayals, concise narrative structures, and appropriate readability), which poses challenges in CLA. In this paper, we propose a method called InstructChild, which augments the LLM with these preferences for adaptation. Specifically, we first obtain the characters' personalities and narrative structure as additional information for fine-grained instruction tuning. Then, we devise a readability metric as the reward to align the LLM with the children's reading level. Finally, a lookahead decoding strategy is applied to improve the readability of the generated text during inference. To support the evaluation of CLA task, we construct the Classic4Children dataset, which comprises both the original and child-friendly versions of the Four Great Classical Novels of Chinese literature. Experimental results show that our InstructChild significantly improves automatic and human evaluation performance.
Learning to Correction: Explainable Feedback Generation for Visual Commonsense Reasoning Distractor
Dec 08, 2024Large multimodal models (LMMs) have shown remarkable performance in the visual commonsense reasoning (VCR) task, which aims to answer a multiple-choice question based on visual commonsense within an image. However, the ability of LMMs to correct potential visual commonsense errors in the distractor upon their occurrence is yet under-explored. Drawing inspiration from how a human teacher crafts challenging distractors to test students' comprehension of the concepts or skills and assists them in identifying and correcting errors toward the answer, we are the pioneering research for LMMs to simulate this error correction process. To this end, we employ GPT-4 as a ``teacher'' to collect the explainable feedback dataset VCR-DF for error correction, which serves as a benchmark to evaluate the ability of LMMs to identify misconceptions and clarify reasons behind the error in VCR distractors toward final answers. In addition, we propose an LMM-based Pedagogical Expert Instructed Feedback Generation (PEIFG) model to incorporate the learnable expert prompts and multimodal instruction as guidance for feedback generation. Experimental results show that our PEIFG significantly outperforms existing LMMs. We believe that our benchmark provides a new direction for evaluating the capabilities of LMMs.
Is Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 04, 2024

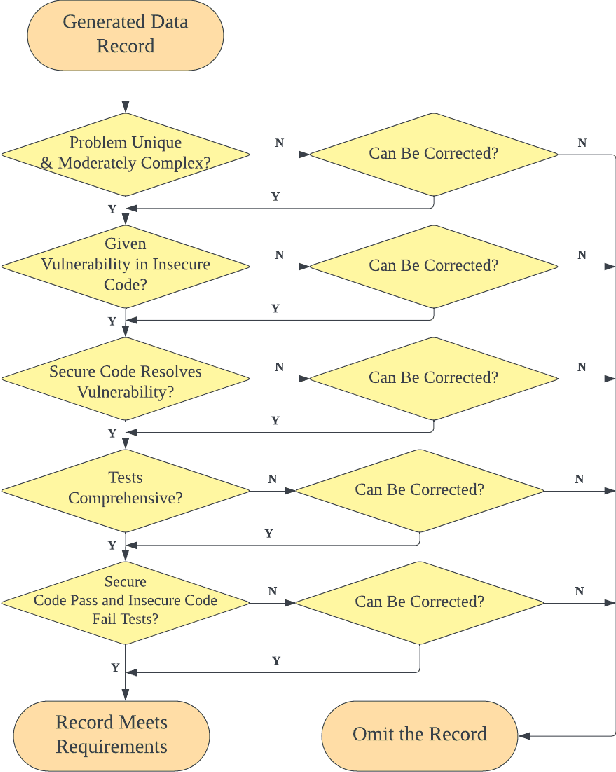

Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 02, 2024Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
UniMEEC: Towards Unified Multimodal Emotion Recognition and Emotion Cause
Mar 30, 2024
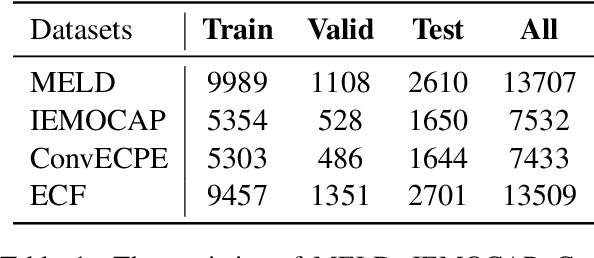
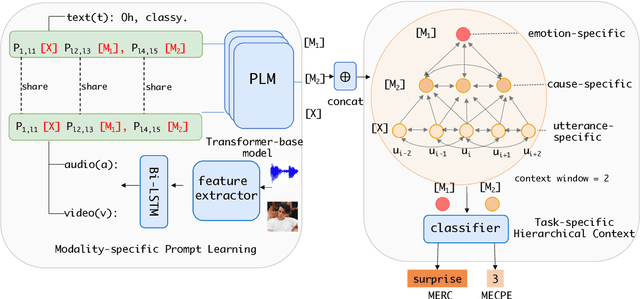
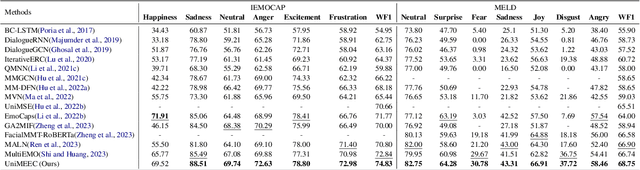
Multimodal emotion recognition in conversation (MERC) and multimodal emotion-cause pair extraction (MECPE) has recently garnered significant attention. Emotions are the expression of affect or feelings; responses to specific events, thoughts, or situations are known as emotion causes. Both are like two sides of a coin, collectively describing human behaviors and intents. However, most existing works treat MERC and MECPE as separate tasks, which may result in potential challenges in integrating emotion and cause in real-world applications. In this paper, we propose a Unified Multimodal Emotion recognition and Emotion-Cause analysis framework (UniMEEC) to explore the causality and complementarity between emotion and emotion cause. Concretely, UniMEEC reformulates the MERC and MECPE tasks as two mask prediction problems, enhancing the interaction between emotion and cause. Meanwhile, UniMEEC shares the prompt learning among modalities for probing modality-specific knowledge from the Pre-trained model. Furthermore, we propose a task-specific hierarchical context aggregation to control the information flow to the task. Experiment results on four public benchmark datasets verify the model performance on MERC and MECPE tasks and achieve consistent improvements compared with state-of-the-art methods.
Enhancing Large Language Models for Secure Code Generation: A Dataset-driven Study on Vulnerability Mitigation
Oct 25, 2023



Large language models (LLMs) have brought significant advancements to code generation, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, introduces the risk of inadvertently propagating security vulnerabilities. To effectively mitigate this concern, this paper presents a comprehensive study focused on evaluating and enhancing code LLMs from a software security perspective. We introduce SecuCoGen\footnote{SecuCoGen has been uploaded as supplemental material and will be made publicly available after publication.}, a meticulously curated dataset targeting 21 critical vulnerability types. SecuCoGen comprises 180 samples and serves as the foundation for conducting experiments on three crucial code-related tasks: code generation, code repair and vulnerability classification, with a strong emphasis on security. Our experimental results reveal that existing models often overlook security concerns during code generation, leading to the generation of vulnerable code. To address this, we propose effective approaches to mitigate the security vulnerabilities and enhance the overall robustness of code generated by LLMs. Moreover, our study identifies weaknesses in existing models' ability to repair vulnerable code, even when provided with vulnerability information. Additionally, certain vulnerability types pose challenges for the models, hindering their performance in vulnerability classification. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.