 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTRL: Prior Transfer Deep Reinforcement Learning for Legged Robots Locomotion
Apr 08, 2025


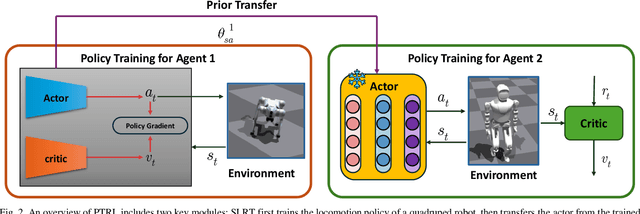
In the field of legged robot motion control, reinforcement learning (RL) holds great promise but faces two major challenges: high computational cost for training individual robots and poor generalization of trained models. To address these problems, this paper proposes a novel framework called Prior Transfer Reinforcement Learning (PTRL), which improves both training efficiency and model transferability across different robots. Drawing inspiration from model transfer techniques in deep learning, PTRL introduces a fine-tuning mechanism that selectively freezes layers of the policy network during transfer, making it the first to apply such a method in RL. The framework consists of three stages: pre-training on a source robot using the Proximal Policy Optimization (PPO) algorithm, transferring the learned policy to a target robot, and fine-tuning with partial network freezing. Extensive experiments on various robot platforms confirm that this approach significantly reduces training time while maintaining or even improving performance. Moreover, the study quantitatively analyzes how the ratio of frozen layers affects transfer results, providing valuable insights into optimizing the process. The experimental outcomes show that PTRL achieves better walking control performance and demonstrates strong generalization and adaptability, offering a promising solution for efficient and scalable RL-based control of legged robots.
Data Driven Automatic Electrical Machine Preliminary Design with Artificial Intelligence Expert Guidance
Nov 18, 2024



This paper presents a data-driven electrical machine design (EMD) framework using wound-rotor synchronous generator (WRSG) as a design example. Unlike traditional preliminary EMD processes that heavily rely on expertise, this framework leverages an artificial-intelligence based expert database, to provide preliminary designs directly from user specifications. Initial data is generated using 2D finite element (FE) machine models by sweeping fundamental design variables including machine length and diameter, enabling scalable machine geometry with machine performance for each design is recorded. This data trains a Metamodel of Optimal Prognosis (MOP)-based surrogate model, which maps design variables to key performance indicators (KPIs). Once trained, guided by metaheuristic algorithms, the surrogate model can generate thousands of geometric scalable designs, covering a wide power range, forming an AI expert database to guide future preliminary design. The framework is validated with a 30kVA WRSG design case. A prebuilt WRSG database, covering power from 10 to 60kVA, is validated by FE simulation. Design No.1138 is selected from database and compared with conventional design. Results show No.1138 achieves a higher power density of 2.21 kVA/kg in just 5 seconds, compared to 2.02 kVA/kg obtained using traditional method, which take several days. The developed AI expert database also serves as a high-quality data source for further developing AI models for automatic electrical machine design.
Is Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 04, 2024

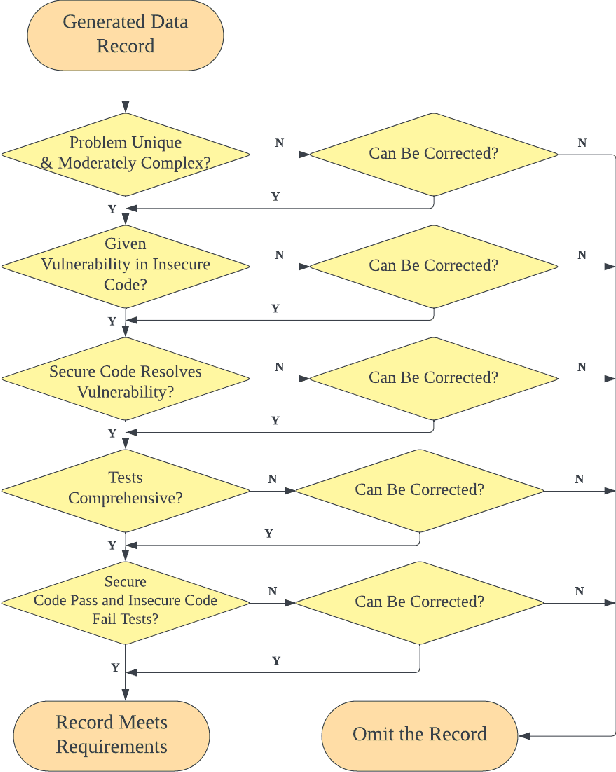

Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 02, 2024Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.