 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAME: Task Agnostic Continual Learning using Multiple Experts
Oct 08, 2022
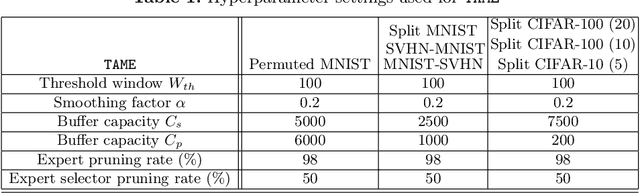

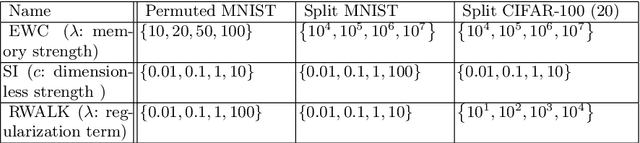
The goal of lifelong learning is to continuously learn from non-stationary distributions, where the non-stationarity is typically imposed by a sequence of distinct tasks. Prior works have mostly considered idealistic settings, where the identity of tasks is known at least at training. In this paper we focus on a fundamentally harder, so-called task-agnostic setting where the task identities are not known and the learning machine needs to infer them from the observations. Our algorithm, which we call TAME (Task-Agnostic continual learning using Multiple Experts), automatically detects the shift in data distributions and switches between task expert networks in an online manner. At training, the strategy for switching between tasks hinges on an extremely simple observation that for each new coming task there occurs a statistically-significant deviation in the value of the loss function that marks the onset of this new task. At inference, the switching between experts is governed by the selector network that forwards the test sample to its relevant expert network. The selector network is trained on a small subset of data drawn uniformly at random. We control the growth of the task expert networks as well as selector network by employing online pruning. Our experimental results show the efficacy of our approach on benchmark continual learning data sets, outperforming the previous task-agnostic methods and even the techniques that admit task identities at both training and testing, while at the same time using a comparable model size.
Efficient Contextual Bandits with Continuous Actions
Jun 10, 2020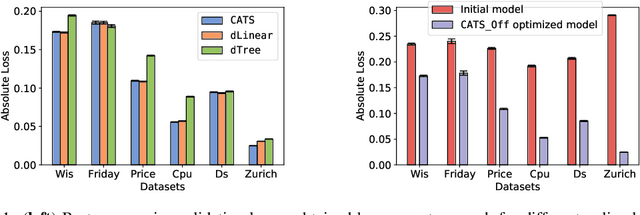
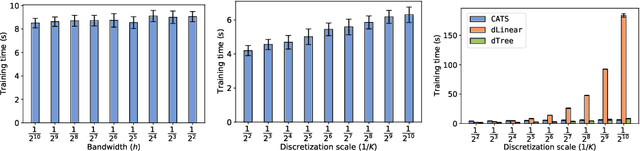
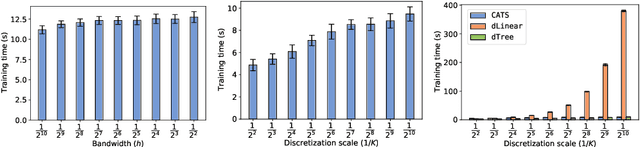
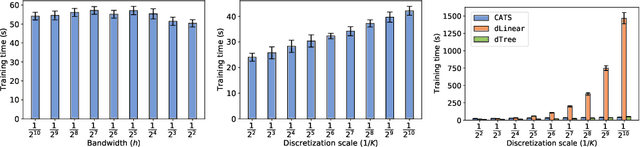
We create a computationally tractable algorithm for contextual bandits with continuous actions having unknown structure. Our reduction-style algorithm composes with most supervised learning representations. We prove that it works in a general sense and verify the new functionality with large-scale experiments.
LdSM: Logarithm-depth Streaming Multi-label Decision Trees
Jun 03, 2019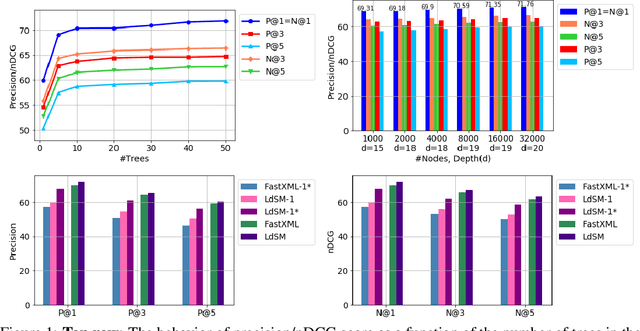
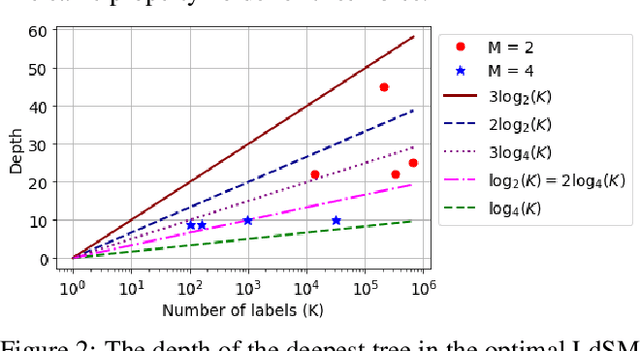
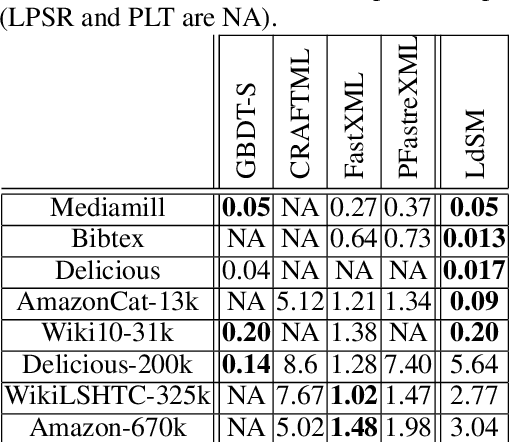
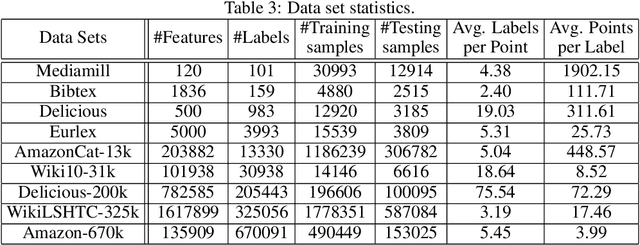
We consider multi-label classification where the goal is to annotate each data point with the most relevant $\textit{subset}$ of labels from an extremely large label set. Efficient annotation can be achieved with balanced tree predictors, i.e. trees with logarithmic-depth in the label complexity, whose leaves correspond to labels. Designing prediction mechanism with such trees for real data applications is non-trivial as it needs to accommodate sending examples to multiple leaves while at the same time sustain high prediction accuracy. In this paper we develop the LdSM algorithm for the construction and training of multi-label decision trees, where in every node of the tree we optimize a novel objective function that favors balanced splits, maintains high class purity of children nodes, and allows sending examples to multiple directions but with a penalty that prevents tree over-growth. Each node of the tree is trained once the previous one is completed leading to a streaming approach for training. We analyze the proposed method theoretically and show that minimizing the objective leads to pure and balanced data splits. Furthermore, we prove that optimizing it results in the monotonic decrease of the error with every split. Experimental results on benchmark data sets demonstrate that our approach achieves high prediction accuracy with logarithmic-depth trees and position LdSM as a competitive tool among existing state-of-the-art tree-based approaches in terms of the statistical performance and prediction time.