 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLdSM: Logarithm-depth Streaming Multi-label Decision Trees
Paper and Code
Jun 03, 2019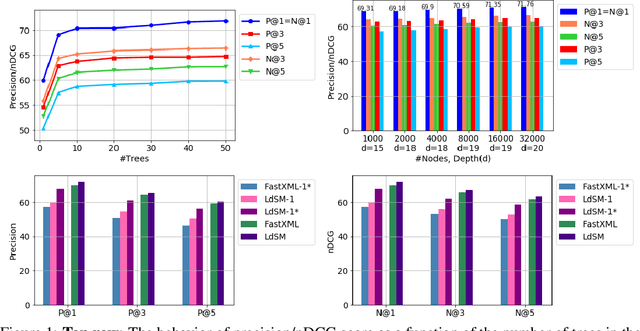
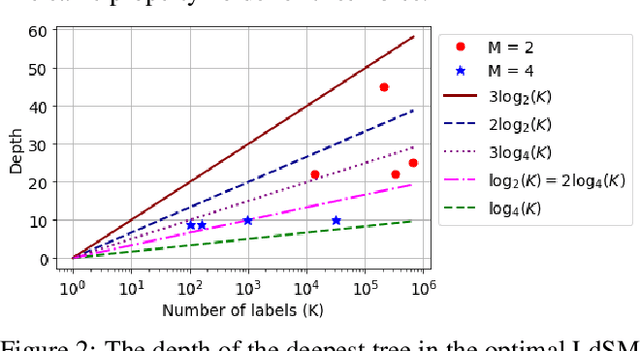
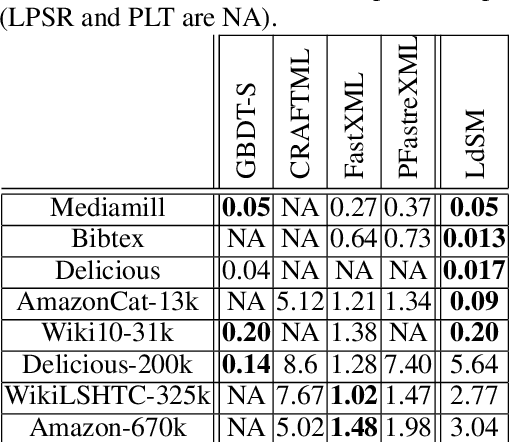
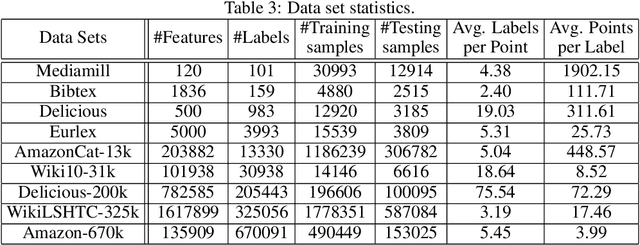
We consider multi-label classification where the goal is to annotate each data point with the most relevant $\textit{subset}$ of labels from an extremely large label set. Efficient annotation can be achieved with balanced tree predictors, i.e. trees with logarithmic-depth in the label complexity, whose leaves correspond to labels. Designing prediction mechanism with such trees for real data applications is non-trivial as it needs to accommodate sending examples to multiple leaves while at the same time sustain high prediction accuracy. In this paper we develop the LdSM algorithm for the construction and training of multi-label decision trees, where in every node of the tree we optimize a novel objective function that favors balanced splits, maintains high class purity of children nodes, and allows sending examples to multiple directions but with a penalty that prevents tree over-growth. Each node of the tree is trained once the previous one is completed leading to a streaming approach for training. We analyze the proposed method theoretically and show that minimizing the objective leads to pure and balanced data splits. Furthermore, we prove that optimizing it results in the monotonic decrease of the error with every split. Experimental results on benchmark data sets demonstrate that our approach achieves high prediction accuracy with logarithmic-depth trees and position LdSM as a competitive tool among existing state-of-the-art tree-based approaches in terms of the statistical performance and prediction time.