 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^3$VAADA: Submodular Subset Selection for Virtual Adversarial Active Domain Adaptation
Paper and Code
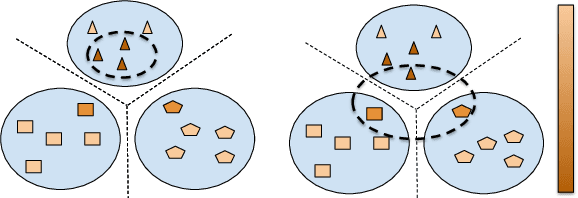
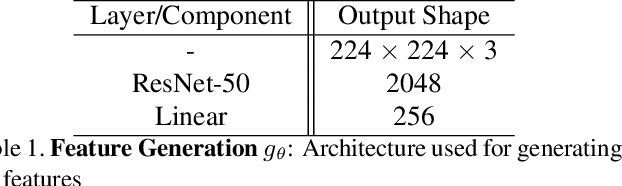
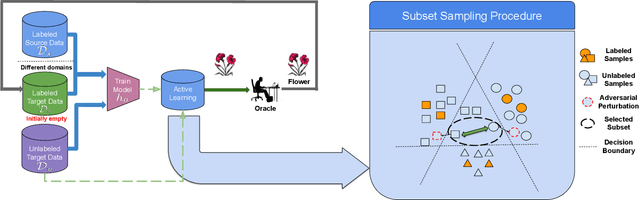

Unsupervised domain adaptation (DA) methods have focused on achieving maximal performance through aligning features from source and target domains without using labeled data in the target domain. Whereas, in the real-world scenario's it might be feasible to get labels for a small proportion of target data. In these scenarios, it is important to select maximally-informative samples to label and find an effective way to combine them with the existing knowledge from source data. Towards achieving this, we propose S$^3$VAADA which i) introduces a novel submodular criterion to select a maximally informative subset to label and ii) enhances a cluster-based DA procedure through novel improvements to effectively utilize all the available data for improving generalization on target. Our approach consistently outperforms the competing state-of-the-art approaches on datasets with varying degrees of domain shifts.