 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Absence withSymptoms that *T* Show up Decades Later to Recover Empty Categories
Paper and Code
Dec 02, 2024
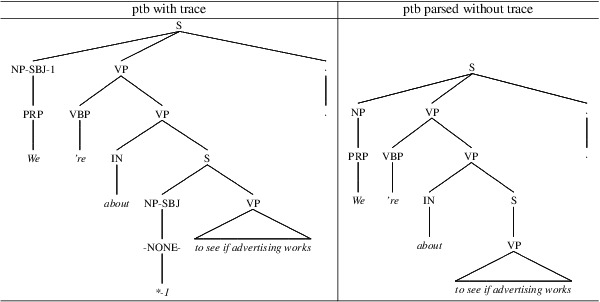
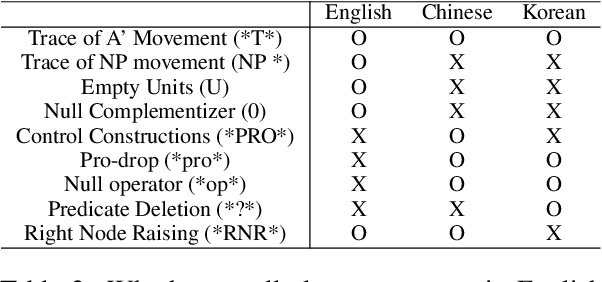
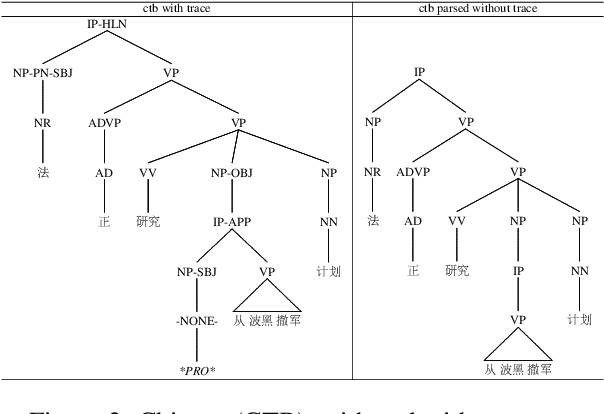
This paper explores null elements in English, Chinese, and Korean Penn treebanks. Null elements contain important syntactic and semantic information, yet they have typically been treated as entities to be removed during language processing tasks, particularly in constituency parsing. Thus, we work towards the removal and, in particular, the restoration of null elements in parse trees. We focus on expanding a rule-based approach utilizing linguistic context information to Chinese, as rule based approaches have historically only been applied to English. We also worked to conduct neural experiments with a language agnostic sequence-to-sequence model to recover null elements for English (PTB), Chinese (CTB) and Korean (KTB). To the best of the authors' knowledge, null elements in three different languages have been explored and compared for the first time. In expanding a rule based approach to Chinese, we achieved an overall F1 score of 80.00, which is comparable to past results in the CTB. In our neural experiments we achieved F1 scores up to 90.94, 85.38 and 88.79 for English, Chinese, and Korean respectively with functional labels.