 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024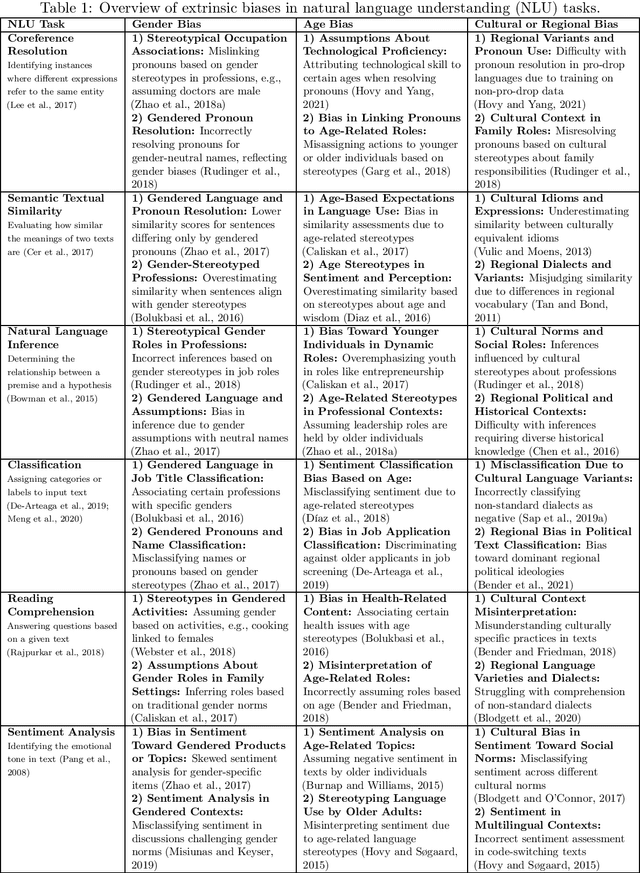
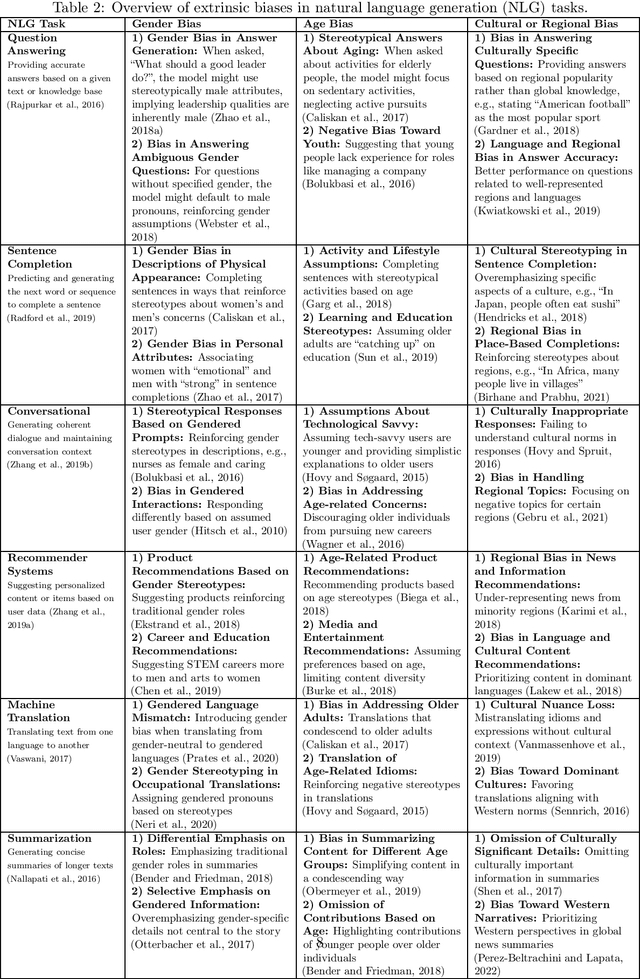
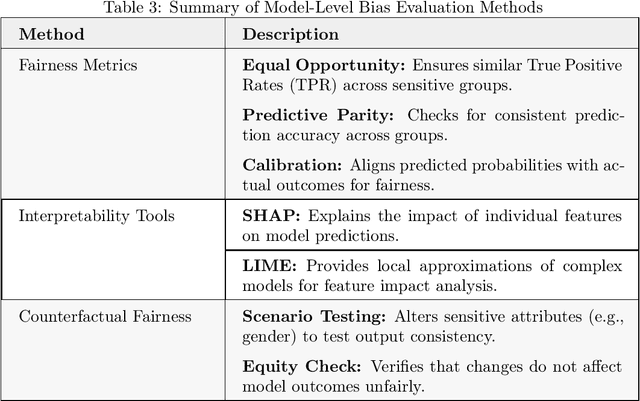

Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.
Advantage Actor-Critic with Reasoner: Explaining the Agent's Behavior from an Exploratory Perspective
Sep 09, 2023
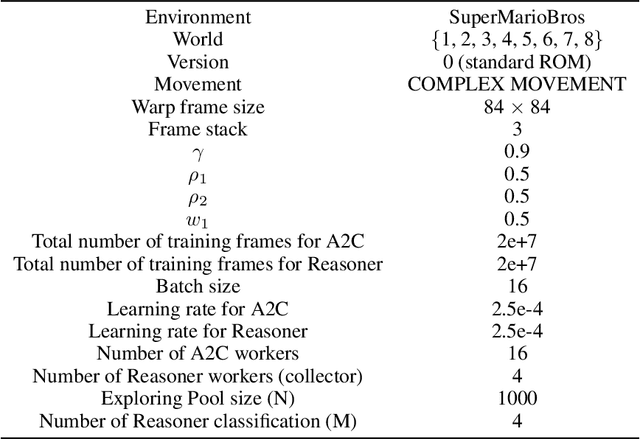
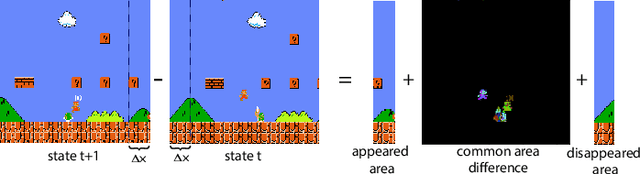
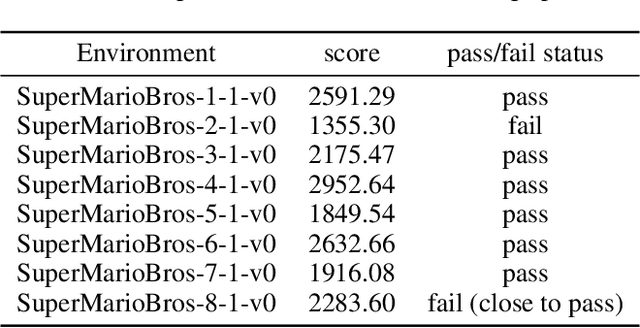
Reinforcement learning (RL) is a powerful tool for solving complex decision-making problems, but its lack of transparency and interpretability has been a major challenge in domains where decisions have significant real-world consequences. In this paper, we propose a novel Advantage Actor-Critic with Reasoner (A2CR), which can be easily applied to Actor-Critic-based RL models and make them interpretable. A2CR consists of three interconnected networks: the Policy Network, the Value Network, and the Reasoner Network. By predefining and classifying the underlying purpose of the actor's actions, A2CR automatically generates a more comprehensive and interpretable paradigm for understanding the agent's decision-making process. It offers a range of functionalities such as purpose-based saliency, early failure detection, and model supervision, thereby promoting responsible and trustworthy RL. Evaluations conducted in action-rich Super Mario Bros environments yield intriguing findings: Reasoner-predicted label proportions decrease for ``Breakout" and increase for ``Hovering" as the exploration level of the RL algorithm intensifies. Additionally, purpose-based saliencies are more focused and comprehensible.