 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024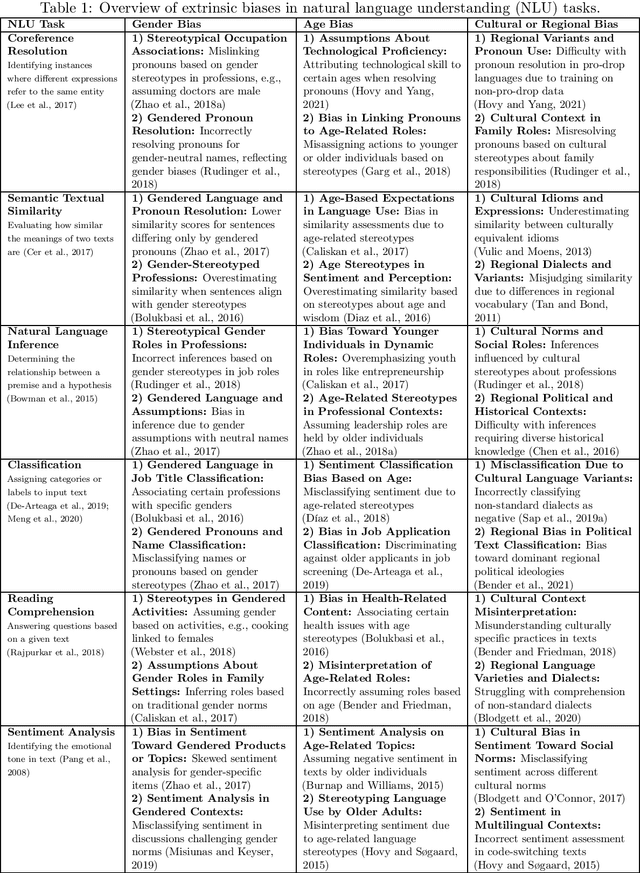
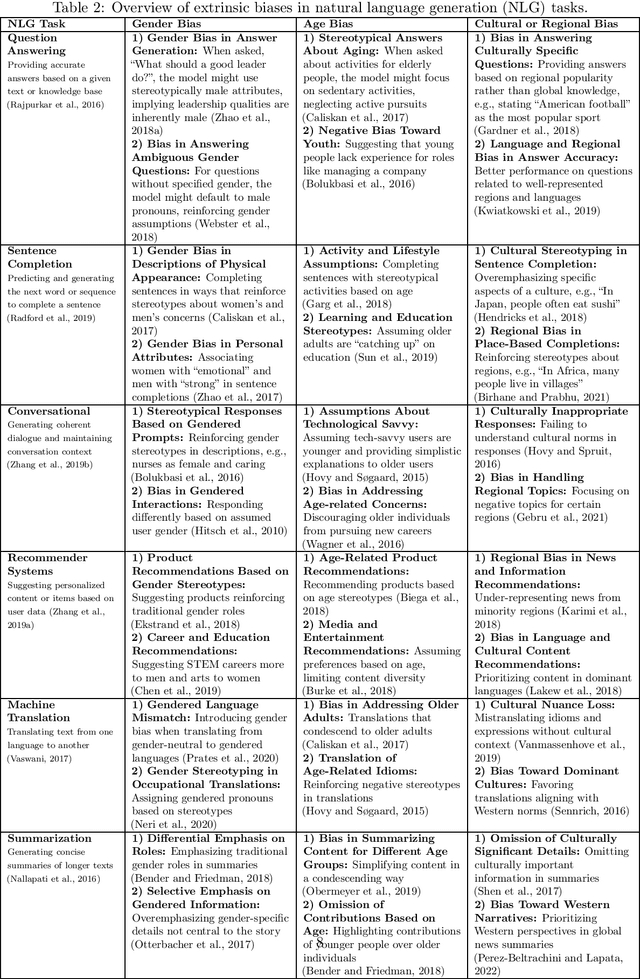
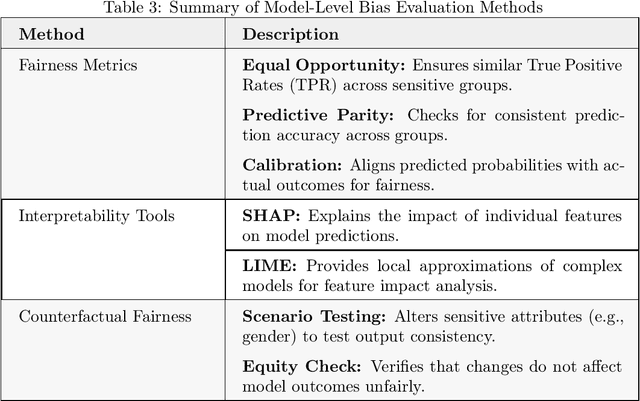

Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.