 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Machine Unlearning
Paper and Code
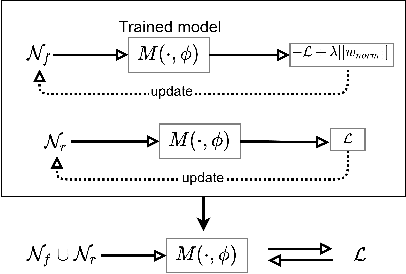
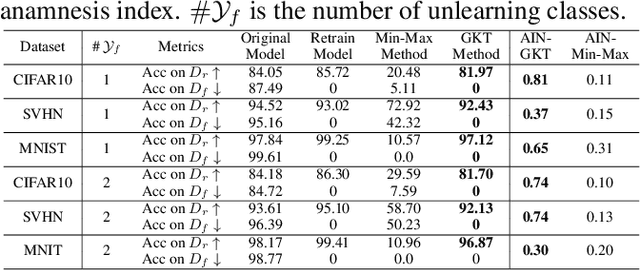
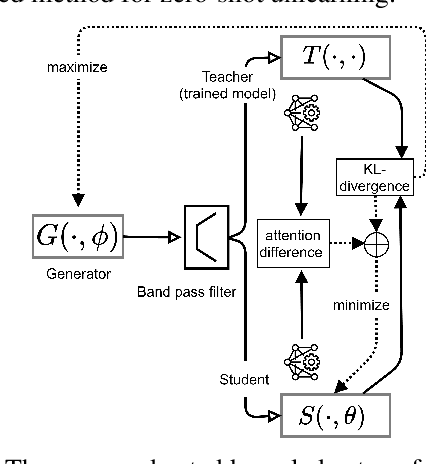
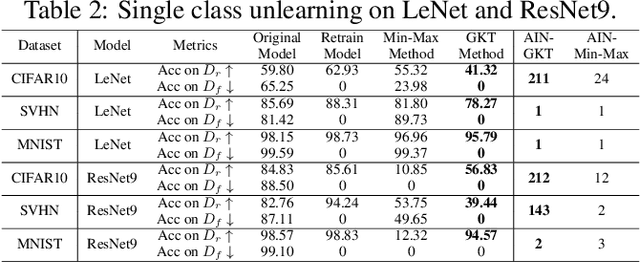
With the introduction of new privacy regulations, machine unlearning is becoming an emerging research problem due to an increasing need for regulatory compliance required for machine learning (ML) applications. Modern privacy regulations grant citizens the right to be forgotten by products, services and companies. This necessitates deletion of data not only from storage archives but also from ML model. The right to be forgotten requests come in the form of removal of a certain set or class of data from the already trained ML model. Practical considerations preclude retraining of the model from scratch minus the deleted data. The few existing studies use the whole training data, or a subset of training data, or some metadata stored during training to update the model weights for unlearning. However, strict regulatory compliance requires time-bound deletion of data. Thus, in many cases, no data related to the training process or training samples may be accessible even for the unlearning purpose. We therefore ask the question: is it possible to achieve unlearning with zero training samples? In this paper, we introduce the novel problem of zero-shot machine unlearning that caters for the extreme but practical scenario where zero original data samples are available for use. We then propose two novel solutions for zero-shot machine unlearning based on (a) error minimizing-maximizing noise and (b) gated knowledge transfer. We also introduce a new evaluation metric, Anamnesis Index (AIN) to effectively measure the quality of the unlearning method. The experiments show promising results for unlearning in deep learning models on benchmark vision data-sets. The source code will be made publicly available.