 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o: Visual perception performance of multimodal large language models in piglet activity understanding
Jun 14, 2024Animal ethology is an crucial aspect of animal research, and animal behavior labeling is the foundation for studying animal behavior. This process typically involves labeling video clips with behavioral semantic tags, a task that is complex, subjective, and multimodal. With the rapid development of multimodal large language models(LLMs), new application have emerged for animal behavior understanding tasks in livestock scenarios. This study evaluates the visual perception capabilities of multimodal LLMs in animal activity recognition. To achieve this, we created piglet test data comprising close-up video clips of individual piglets and annotated full-shot video clips. These data were used to assess the performance of four multimodal LLMs-Video-LLaMA, MiniGPT4-Video, Video-Chat2, and GPT-4 omni (GPT-4o)-in piglet activity understanding. Through comprehensive evaluation across five dimensions, including counting, actor referring, semantic correspondence, time perception, and robustness, we found that while current multimodal LLMs require improvement in semantic correspondence and time perception, they have initially demonstrated visual perception capabilities for animal activity recognition. Notably, GPT-4o showed outstanding performance, with Video-Chat2 and GPT-4o exhibiting significantly better semantic correspondence and time perception in close-up video clips compared to full-shot clips. The initial evaluation experiments in this study validate the potential of multimodal large language models in livestock scene video understanding and provide new directions and references for future research on animal behavior video understanding. Furthermore, by deeply exploring the influence of visual prompts on multimodal large language models, we expect to enhance the accuracy and efficiency of animal behavior recognition in livestock scenarios through human visual processing methods.
Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras
Nov 22, 2021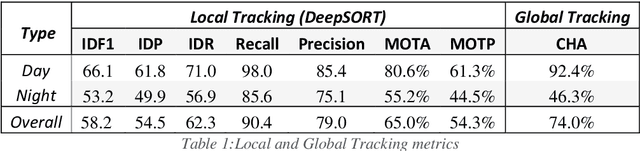
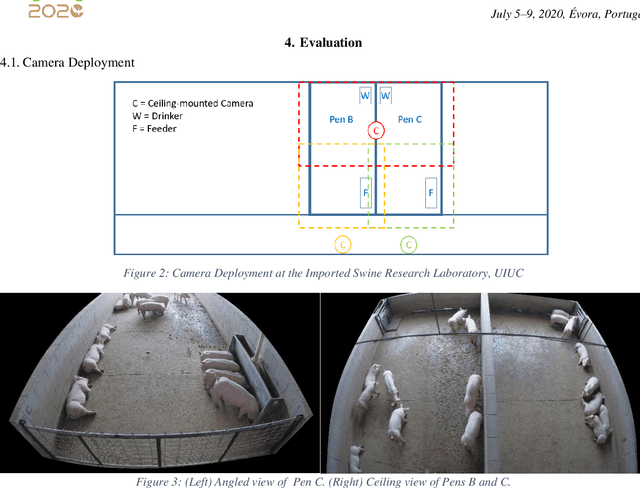


Increasing demand for meat products combined with farm labor shortages has resulted in a need to develop new real-time solutions to monitor animals effectively. Significant progress has been made in continuously locating individual pigs using tracking-by-detection methods. However, these methods fail for oblong pens because a single fixed camera does not cover the entire floor at adequate resolution. We address this problem by using multiple cameras, placed such that the visual fields of adjacent cameras overlap, and together they span the entire floor. Avoiding breaks in tracking requires inter-camera handover when a pig crosses from one camera's view into that of an adjacent camera. We identify the adjacent camera and the shared pig location on the floor at the handover time using inter-view homography. Our experiments involve two grow-finish pens, housing 16-17 pigs each, and three RGB cameras. Our algorithm first detects pigs using a deep learning-based object detection model (YOLO) and creates their local tracking IDs using a multi-object tracking algorithm (DeepSORT). We then use inter-camera shared locations to match multiple views and generate a global ID for each pig that holds throughout tracking. To evaluate our approach, we provide five two-minutes long video sequences with fully annotated global identities. We track pigs in a single camera view with a Multi-Object Tracking Accuracy and Precision of 65.0% and 54.3% respectively and achieve a Camera Handover Accuracy of 74.0%. We open-source our code and annotated dataset at https://github.com/AIFARMS/multi-camera-pig-tracking