 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o: Visual perception performance of multimodal large language models in piglet activity understanding
Jun 14, 2024Animal ethology is an crucial aspect of animal research, and animal behavior labeling is the foundation for studying animal behavior. This process typically involves labeling video clips with behavioral semantic tags, a task that is complex, subjective, and multimodal. With the rapid development of multimodal large language models(LLMs), new application have emerged for animal behavior understanding tasks in livestock scenarios. This study evaluates the visual perception capabilities of multimodal LLMs in animal activity recognition. To achieve this, we created piglet test data comprising close-up video clips of individual piglets and annotated full-shot video clips. These data were used to assess the performance of four multimodal LLMs-Video-LLaMA, MiniGPT4-Video, Video-Chat2, and GPT-4 omni (GPT-4o)-in piglet activity understanding. Through comprehensive evaluation across five dimensions, including counting, actor referring, semantic correspondence, time perception, and robustness, we found that while current multimodal LLMs require improvement in semantic correspondence and time perception, they have initially demonstrated visual perception capabilities for animal activity recognition. Notably, GPT-4o showed outstanding performance, with Video-Chat2 and GPT-4o exhibiting significantly better semantic correspondence and time perception in close-up video clips compared to full-shot clips. The initial evaluation experiments in this study validate the potential of multimodal large language models in livestock scene video understanding and provide new directions and references for future research on animal behavior video understanding. Furthermore, by deeply exploring the influence of visual prompts on multimodal large language models, we expect to enhance the accuracy and efficiency of animal behavior recognition in livestock scenarios through human visual processing methods.
PointSCNet: Point Cloud Structure and Correlation Learning Based on Space Filling Curve-Guided Sampling
Feb 21, 2022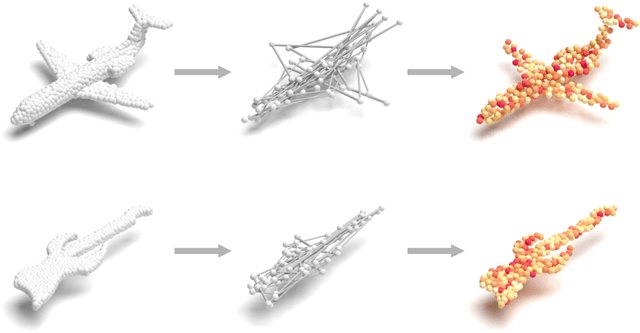
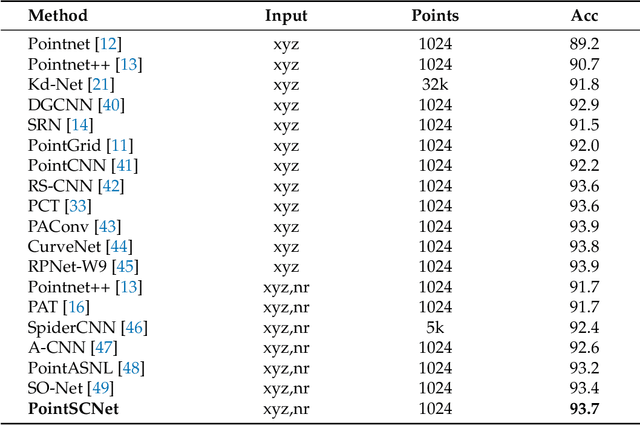
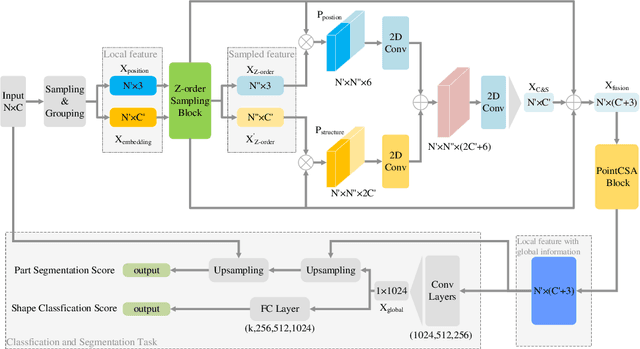
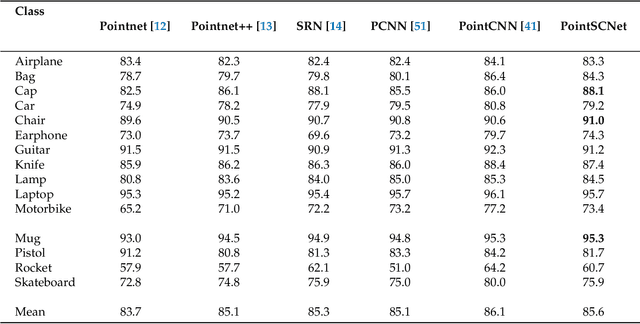
Geometrical structures and the internal local region relationship, such as symmetry, regular array, junction, etc., are essential for understanding a 3D shape. This paper proposes a point cloud feature extraction network named PointSCNet, to capture the geometrical structure information and local region correlation information of a point cloud. The PointSCNet consists of three main modules: the space-filling curve-guided sampling module, the information fusion module, and the channel-spatial attention module. The space-filling curve-guided sampling module uses Z-order curve coding to sample points that contain geometrical correlation. The information fusion module uses a correlation tensor and a set of skip connections to fuse the structure and correlation information. The channel-spatial attention module enhances the representation of key points and crucial feature channels to refine the network. The proposed PointSCNet is evaluated on shape classification and part segmentation tasks. The experimental results demonstrate that the PointSCNet outperforms or is on par with state-of-the-art methods by learning the structure and correlation of point clouds effectively.