 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Camera Pose Augmentation for View Generalization in Robotic Policy Learning
Mar 31, 2026Prevailing 2D-centric visuomotor policies exhibit a pronounced deficiency in novel view generalization, as their reliance on static observations hinders consistent action mapping across unseen views. In response, we introduce GenSplat, a feed-forward 3D Gaussian Splatting framework that facilitates view-generalized policy learning through novel view rendering. GenSplat employs a permutation-equivariant architecture to reconstruct high-fidelity 3D scenes from sparse, uncalibrated inputs in a single forward pass. To ensure structural integrity, we design a 3D-prior distillation strategy that regularizes the 3DGS optimization, preventing the geometric collapse typical of purely photometric supervision. By rendering diverse synthetic views from these stable 3D representations, we systematically augment the observational manifold during training. This augmentation forces the policy to ground its decisions in underlying 3D structures, thereby ensuring robust execution under severe spatial perturbations where baselines severely degrade.
SAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
PointSCNet: Point Cloud Structure and Correlation Learning Based on Space Filling Curve-Guided Sampling
Feb 21, 2022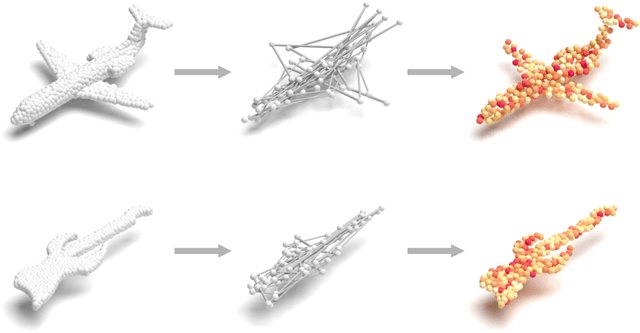
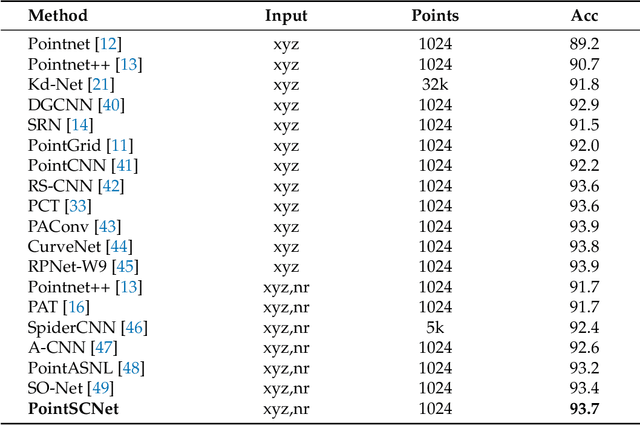
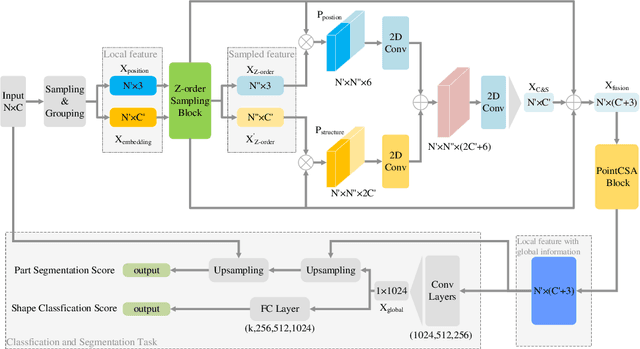
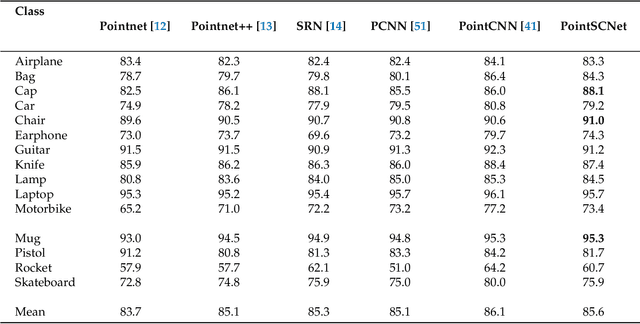
Geometrical structures and the internal local region relationship, such as symmetry, regular array, junction, etc., are essential for understanding a 3D shape. This paper proposes a point cloud feature extraction network named PointSCNet, to capture the geometrical structure information and local region correlation information of a point cloud. The PointSCNet consists of three main modules: the space-filling curve-guided sampling module, the information fusion module, and the channel-spatial attention module. The space-filling curve-guided sampling module uses Z-order curve coding to sample points that contain geometrical correlation. The information fusion module uses a correlation tensor and a set of skip connections to fuse the structure and correlation information. The channel-spatial attention module enhances the representation of key points and crucial feature channels to refine the network. The proposed PointSCNet is evaluated on shape classification and part segmentation tasks. The experimental results demonstrate that the PointSCNet outperforms or is on par with state-of-the-art methods by learning the structure and correlation of point clouds effectively.