 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignSeg: Feature-Aligned Segmentation Networks
Paper and Code

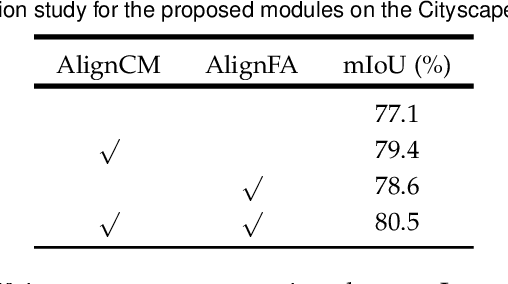
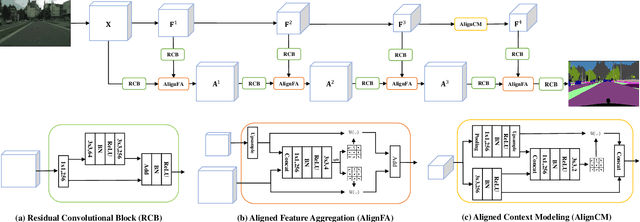
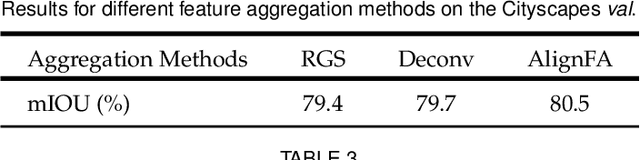
Aggregating features in terms of different convolutional blocks or contextual embeddings has been proven to be an effective way to strengthen feature representations for semantic segmentation. However, most of the current popular network architectures tend to ignore the misalignment issues during the feature aggregation process caused by 1) step-by-step downsampling operations, and 2) indiscriminate contextual information fusion. In this paper, we explore the principles in addressing such feature misalignment issues and inventively propose Feature-Aligned Segmentation Networks (AlignSeg). AlignSeg consists of two primary modules, i.e., the Aligned Feature Aggregation (AlignFA) module and the Aligned Context Modeling (AlignCM) module. First, AlignFA adopts a simple learnable interpolation strategy to learn transformation offsets of pixels, which can effectively relieve the feature misalignment issue caused by multiresolution feature aggregation. Second, with the contextual embeddings in hand, AlignCM enables each pixel to choose private custom contextual information in an adaptive manner, making the contextual embeddings aligned better to provide appropriate guidance. We validate the effectiveness of our AlignSeg network with extensive experiments on Cityscapes and ADE20K, achieving new state-of-the-art mIoU scores of 82.6% and 45.95%, respectively. Our source code will be made available.