 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision-Language Models Replace Human Annotators: A Case Study with CelebA Dataset
Oct 12, 2024This study evaluates the capability of Vision-Language Models (VLMs) in image data annotation by comparing their performance on the CelebA dataset in terms of quality and cost-effectiveness against manual annotation. Annotations from the state-of-the-art LLaVA-NeXT model on 1000 CelebA images are in 79.5% agreement with the original human annotations. Incorporating re-annotations of disagreed cases into a majority vote boosts AI annotation consistency to 89.1% and even higher for more objective labels. Cost assessments demonstrate that AI annotation significantly reduces expenditures compared to traditional manual methods -- representing less than 1% of the costs for manual annotation in the CelebA dataset. These findings support the potential of VLMs as a viable, cost-effective alternative for specific annotation tasks, reducing both financial burden and ethical concerns associated with large-scale manual data annotation. The AI annotations and re-annotations utilized in this study are available on https://github.com/evev2024/EVEV2024_CelebA.
Deep Learning for 3D Point Cloud Understanding: A Survey
Sep 18, 2020
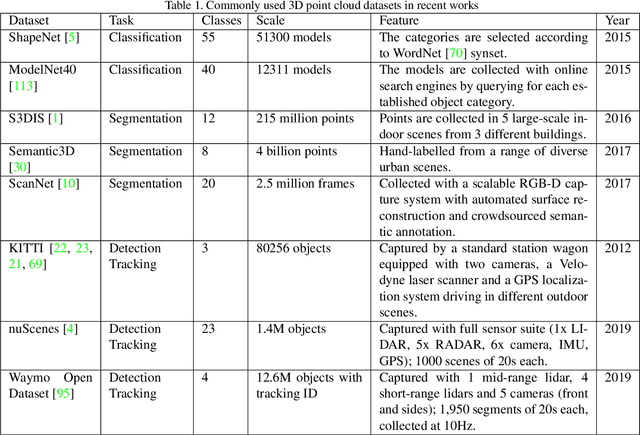
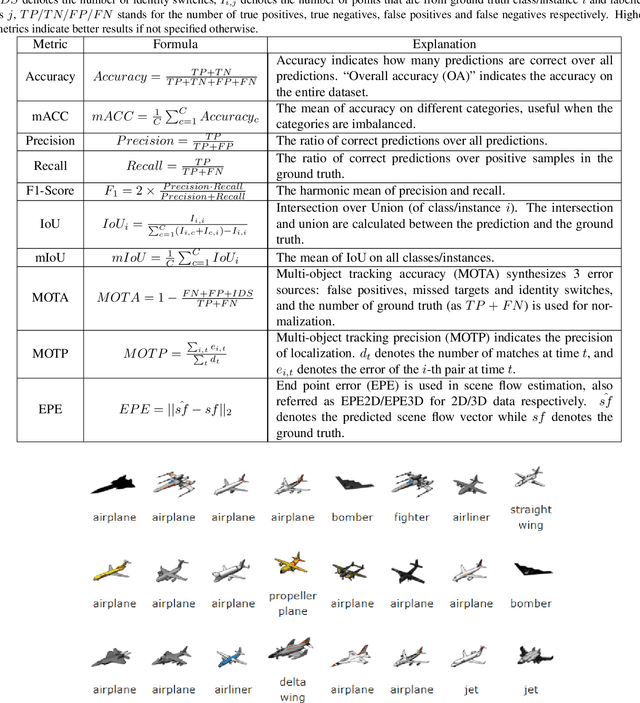
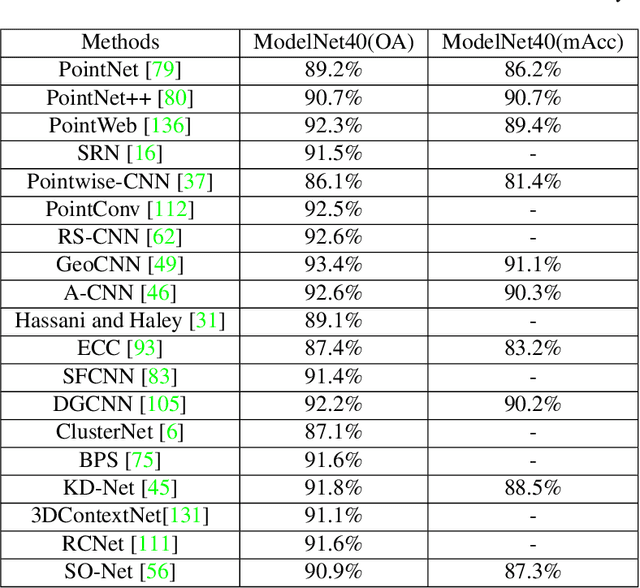
The development of practical applications, such as autonomous driving and robotics, has brought increasing attention to 3D point cloud understanding. While deep learning has achieved remarkable success on image-based tasks, there are many unique challenges faced by deep neural networks in processing massive, unstructured and noisy 3D points. To demonstrate the latest progress of deep learning for 3D point cloud understanding, this paper summarizes recent remarkable research contributions in this area from several different directions (classification, segmentation, detection, tracking, flow estimation, registration, augmentation and completion), together with commonly used datasets, metrics and state-of-the-art performances. More information regarding this survey can be found at: https://github.com/SHI-Labs/3D-Point-Cloud-Learning.
SkyNet: a Hardware-Efficient Method for Object Detection and Tracking on Embedded Systems
Sep 20, 2019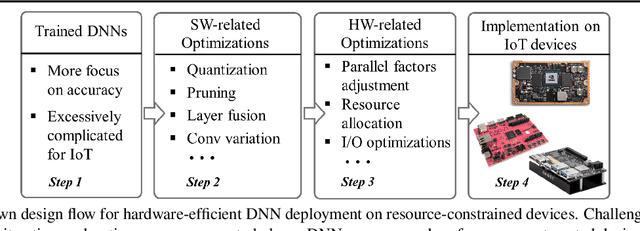
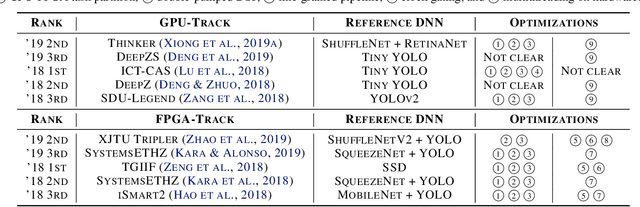

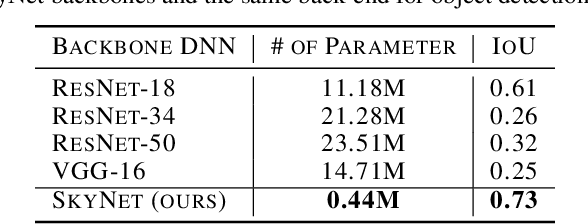
Developing object detection and tracking on resource-constrained embedded systems is challenging. While object detection is one of the most compute-intensive tasks from the artificial intelligence domain, it is only allowed to use limited computation and memory resources on embedded devices. In the meanwhile, such resource-constrained implementations are often required to satisfy additional demanding requirements such as real-time response, high-throughput performance, and reliable inference accuracy. To overcome these challenges, we propose SkyNet, a hardware-efficient method to deliver the state-of-the-art detection accuracy and speed for embedded systems. Instead of following the common top-down flow for compact DNN design, SkyNet provides a bottom-up DNN design approach with comprehensive understanding of the hardware constraints at the very beginning to deliver hardware-efficient DNNs. The effectiveness of SkyNet is demonstrated by winning the extremely competitive System Design Contest for low power object detection in the 56th IEEE/ACM Design Automation Conference (DAC-SDC), where our SkyNet significantly outperforms all other 100+ competitors: it delivers 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 embedded GPU; and 0.716 IoU and 25.05 FPS on an Ultra96 embedded FPGA. The evaluation of SkyNet is also extended to GOT-10K, a recent large-scale high-diversity benchmark for generic object tracking in the wild. For state-of-the-art object trackers SiamRPN++ and SiamMask, where ResNet-50 is employed as the backbone, implementations using our SkyNet as the backbone DNN are 1.60X and 1.73X faster with better or similar accuracy when running on a 1080Ti GPU, and 37.20X smaller in terms of parameter size for significantly better memory and storage footprint.
SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection
Jul 09, 2019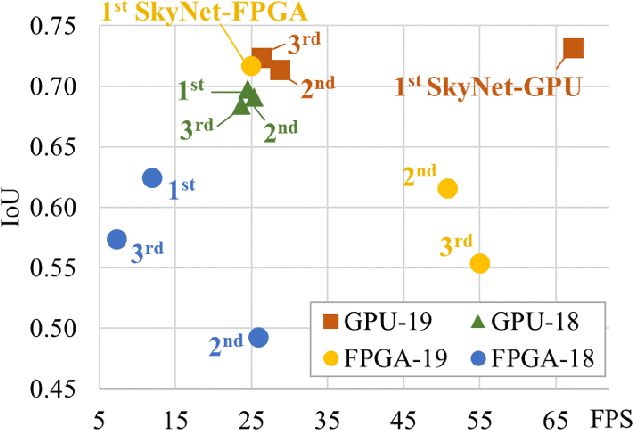



Developing artificial intelligence (AI) at the edge is always challenging, since edge devices have limited computation capability and memory resources but need to meet demanding requirements, such as real-time processing, high throughput performance, and high inference accuracy. To overcome these challenges, we propose SkyNet, an extremely lightweight DNN with 12 convolutional (Conv) layers and only 1.82 megabyte (MB) of parameters following a bottom-up DNN design approach. SkyNet is demonstrated in the 56th IEEE/ACM Design Automation Conference System Design Contest (DAC-SDC), a low power object detection challenge in images captured by unmanned aerial vehicles (UAVs). SkyNet won the first place award for both the GPU and FPGA tracks of the contest: we deliver 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 GPU and deliver 0.716 IoU and 25.05 FPS on an Ultra96 FPGA.