 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLNet: Landmark Driven Fetching and Learning Network for Faithful Talking Facial Animation Synthesis
Paper and Code
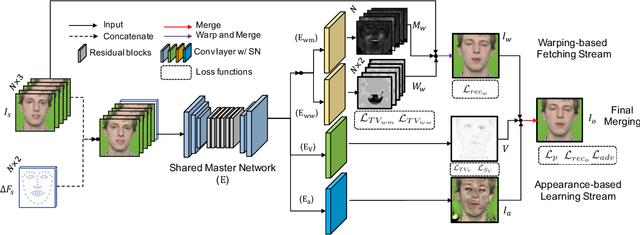
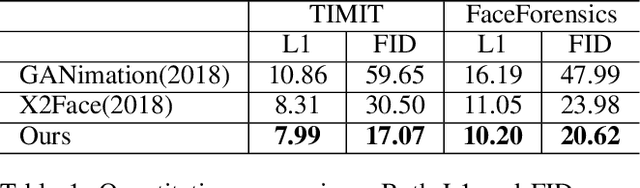


Talking face synthesis has been widely studied in either appearance-based or warping-based methods. Previous works mostly utilize single face image as a source, and generate novel facial animations by merging other person's facial features. However, some facial regions like eyes or teeth, which may be hidden in the source image, can not be synthesized faithfully and stably. In this paper, We present a landmark driven two-stream network to generate faithful talking facial animation, in which more facial details are created, preserved and transferred from multiple source images instead of a single one. Specifically, we propose a network consisting of a learning and fetching stream. The fetching sub-net directly learns to attentively warp and merge facial regions from five source images of distinctive landmarks, while the learning pipeline renders facial organs from the training face space to compensate. Compared to baseline algorithms, extensive experiments demonstrate that the proposed method achieves a higher performance both quantitatively and qualitatively. Codes are at https://github.com/kgu3/FLNet_AAAI2020.