Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Algorithm for Finite Stochastic Partial Monitoring
Jun 27, 2012
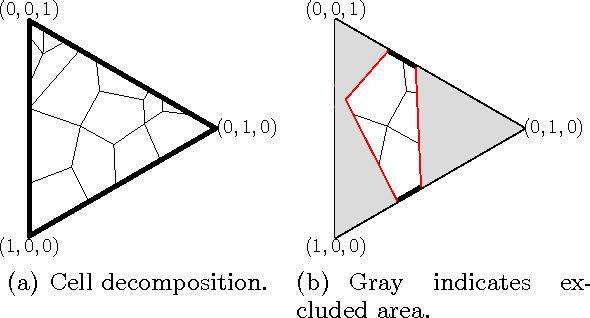
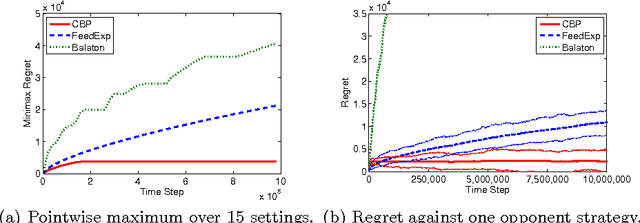
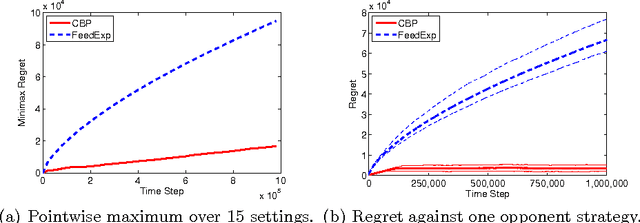
We present a new anytime algorithm that achieves near-optimal regret for any instance of finite stochastic partial monitoring. In particular, the new algorithm achieves the minimax regret, within logarithmic factors, for both "easy" and "hard" problems. For easy problems, it additionally achieves logarithmic individual regret. Most importantly, the algorithm is adaptive in the sense that if the opponent strategy is in an "easy region" of the strategy space then the regret grows as if the problem was easy. As an implication, we show that under some reasonable additional assumptions, the algorithm enjoys an O(\sqrt{T}) regret in Dynamic Pricing, proven to be hard by Bartok et al. (2011).
* Appears in Proceedings of the 29th International Conference on
Machine Learning (ICML 2012)
Via