 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Inspired Fragmentation and Recall to Overcome Catastrophic Forgetting in Curiosity
Paper and Code
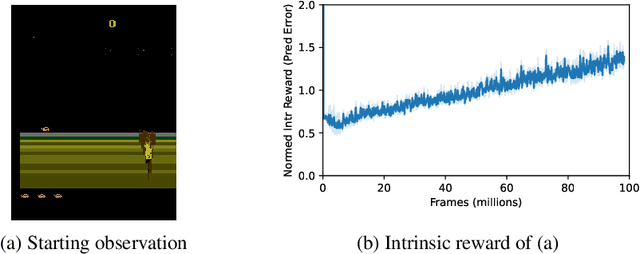
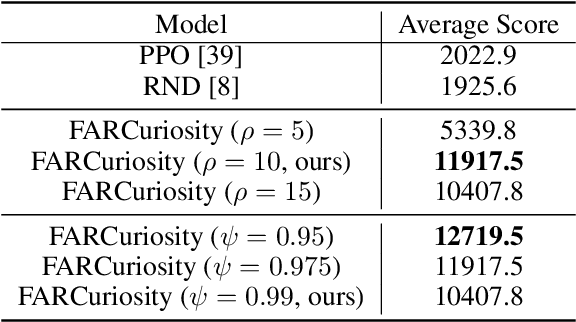
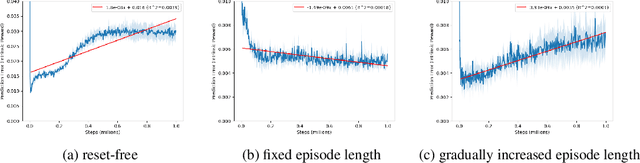

Deep reinforcement learning methods exhibit impressive performance on a range of tasks but still struggle on hard exploration tasks in large environments with sparse rewards. To address this, intrinsic rewards can be generated using forward model prediction errors that decrease as the environment becomes known, and incentivize an agent to explore novel states. While prediction-based intrinsic rewards can help agents solve hard exploration tasks, they can suffer from catastrophic forgetting and actually increase at visited states. We first examine the conditions and causes of catastrophic forgetting in grid world environments. We then propose a new method FARCuriosity, inspired by how humans and animals learn. The method depends on fragmentation and recall: an agent fragments an environment based on surprisal, and uses different local curiosity modules (prediction-based intrinsic reward functions) for each fragment so that modules are not trained on the entire environment. At each fragmentation event, the agent stores the current module in long-term memory (LTM) and either initializes a new module or recalls a previously stored module based on its match with the current state. With fragmentation and recall, FARCuriosity achieves less forgetting and better overall performance in games with varied and heterogeneous environments in the Atari benchmark suite of tasks. Thus, this work highlights the problem of catastrophic forgetting in prediction-based curiosity methods and proposes a solution.