 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Policies for Software-Defined MDPs
Dec 21, 2020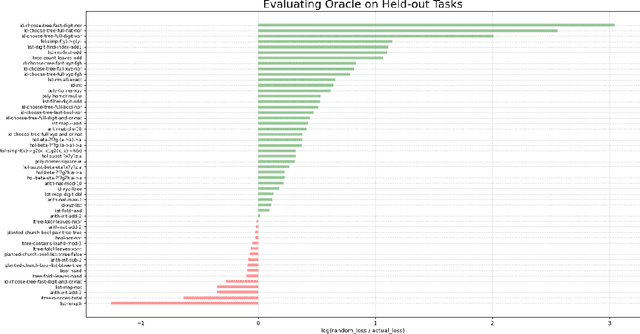
We introduce a new programming paradigm called oracle-guided decision programming in which a program specifies a Markov Decision Process (MDP) and the language provides a universal policy. We prototype a new programming language, Dodona, that manifests this paradigm using a primitive 'choose' representing nondeterministic choice. The Dodona interpreter returns either a value or a choicepoint that includes a lossless encoding of all information necessary in principle to make an optimal decision. Meta-interpreters query Dodona's (neural) oracle on these choicepoints to get policy and value estimates, which they can use to perform heuristic search on the underlying MDP. We demonstrate Dodona's potential for zero-shot heuristic guidance by meta-learning over hundreds of synthetic tasks that simulate basic operations over lists, trees, Church datastructures, polynomials, first-order terms and higher-order terms.
Pythia: Grammar-Based Fuzzing of REST APIs with Coverage-guided Feedback and Learning-based Mutations
May 23, 2020
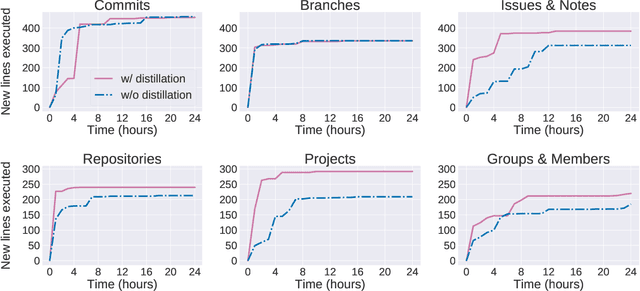
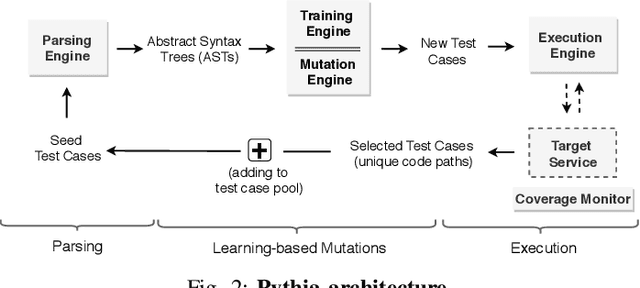

This paper introduces Pythia, the first fuzzer that augments grammar-based fuzzing with coverage-guided feedback and a learning-based mutation strategy for stateful REST API fuzzing. Pythia uses a statistical model to learn common usage patterns of a target REST API from structurally valid seed inputs. It then generates learning-based mutations by injecting a small amount of noise deviating from common usage patterns while still maintaining syntactic validity. Pythia's mutation strategy helps generate grammatically valid test cases and coverage-guided feedback helps prioritize the test cases that are more likely to find bugs. We present experimental evaluation on three production-scale, open-source cloud services showing that Pythia outperforms prior approaches both in code coverage and new bugs found. Using Pythia, we found 29 new bugs which we are in the process of reporting to the respective service owners.
Deep Reinforcement Fuzzing
Jan 14, 2018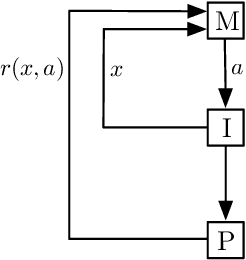


Fuzzing is the process of finding security vulnerabilities in input-processing code by repeatedly testing the code with modified inputs. In this paper, we formalize fuzzing as a reinforcement learning problem using the concept of Markov decision processes. This in turn allows us to apply state-of-the-art deep Q-learning algorithms that optimize rewards, which we define from runtime properties of the program under test. By observing the rewards caused by mutating with a specific set of actions performed on an initial program input, the fuzzing agent learns a policy that can next generate new higher-reward inputs. We have implemented this new approach, and preliminary empirical evidence shows that reinforcement fuzzing can outperform baseline random fuzzing.
Learn&Fuzz: Machine Learning for Input Fuzzing
Jan 25, 2017

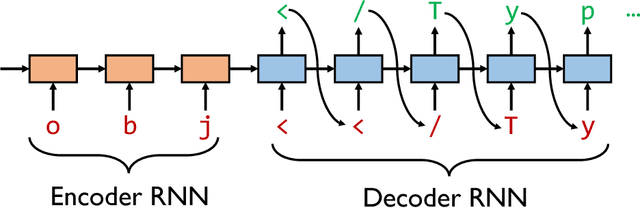
Fuzzing consists of repeatedly testing an application with modified, or fuzzed, inputs with the goal of finding security vulnerabilities in input-parsing code. In this paper, we show how to automate the generation of an input grammar suitable for input fuzzing using sample inputs and neural-network-based statistical machine-learning techniques. We present a detailed case study with a complex input format, namely PDF, and a large complex security-critical parser for this format, namely, the PDF parser embedded in Microsoft's new Edge browser. We discuss (and measure) the tension between conflicting learning and fuzzing goals: learning wants to capture the structure of well-formed inputs, while fuzzing wants to break that structure in order to cover unexpected code paths and find bugs. We also present a new algorithm for this learn&fuzz challenge which uses a learnt input probability distribution to intelligently guide where to fuzz inputs.