 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Pronunciation Analysis in Sung Utterances
Jun 21, 2021
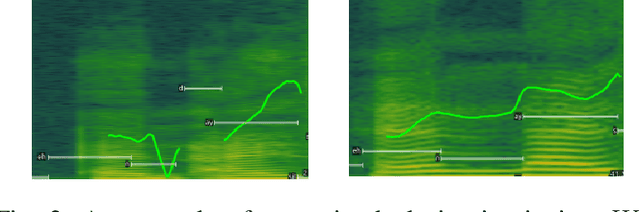
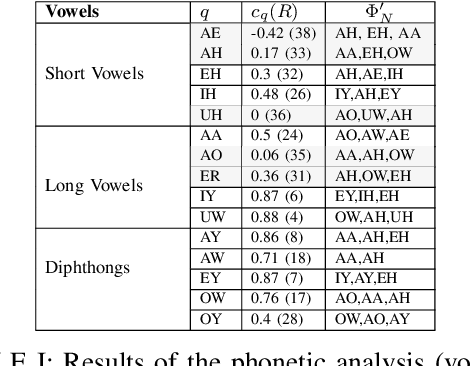
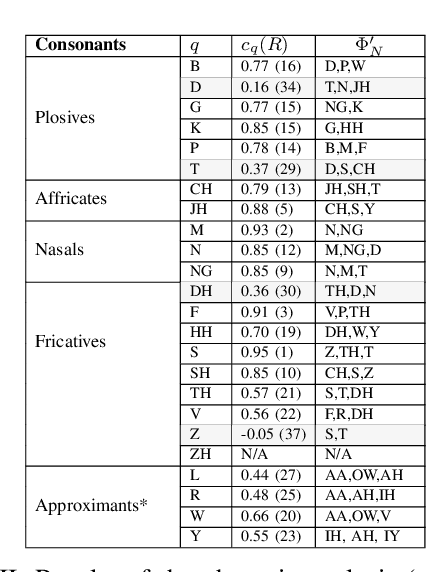
Recent automatic lyrics transcription (ALT) approaches focus on building stronger acoustic models or in-domain language models, while the pronunciation aspect is seldom touched upon. This paper applies a novel computational analysis on the pronunciation variances in sung utterances and further proposes a new pronunciation model adapted for singing. The singing-adapted model is tested on multiple public datasets via word recognition experiments. It performs better than the standard speech dictionary in all settings reporting the best results on ALT in a capella recordings using n-gram language models. For reproducibility, we share the sentence-level annotations used in testing, providing a new benchmark evaluation set for ALT.
Automatic Lyrics Transcription using Dilated Convolutional Neural Networks with Self-Attention
Jul 24, 2020
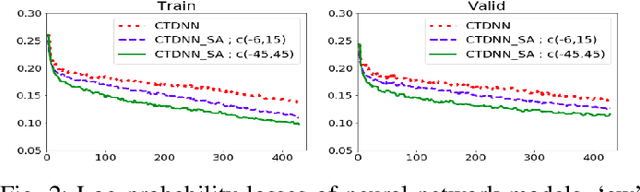
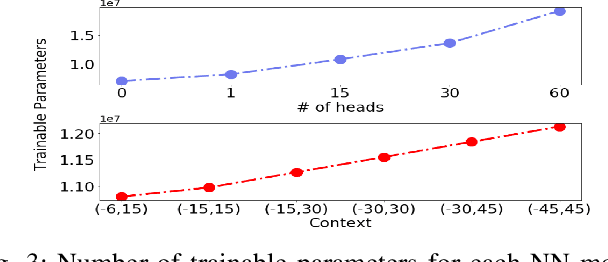
Speech recognition is a well developed research field so that the current state of the art systems are being used in many applications in the software industry, yet as by today, there still does not exist such robust system for the recognition of words and sentences from singing voice. This paper proposes a complete pipeline for this task which may commonly be referred as automatic lyrics transcription (ALT). We have trained convolutional time-delay neural networks with self-attention on monophonic karaoke recordings using a sequence classification objective for building the acoustic model. The dataset used in this study, DAMP - Sing! 300x30x2 [1] is filtered to have songs with only English lyrics. Different language models are tested including MaxEnt and Recurrent Neural Networks based methods which are trained on the lyrics of pop songs in English. An in-depth analysis of the self-attention mechanism is held while tuning its context width and the number of attention heads. Using the best settings, our system achieves notable improvement to the state-of-the-art in ALT and provides a new baseline for the task.