 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Conditional Representation Learning for Drum Sample Retrieval by Vocalisation
Apr 10, 2022
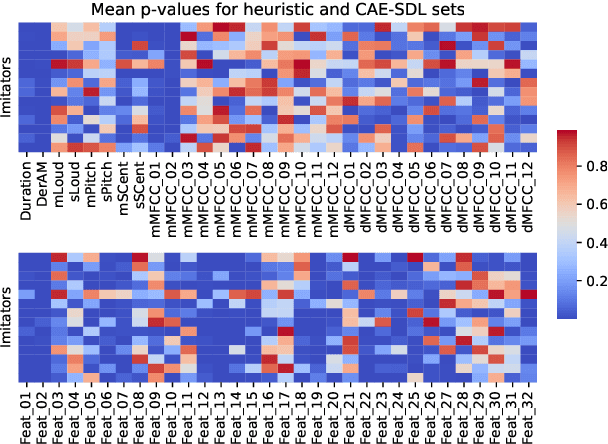
Imitating musical instruments with the human voice is an efficient way of communicating ideas between music producers, from sketching melody lines to clarifying desired sonorities. For this reason, there is an increasing interest in building applications that allow artists to efficiently pick target samples from big sound libraries just by imitating them vocally. In this study, we investigated the potential of conditional autoencoder models to learn informative features for Drum Sample Retrieval by Vocalisation (DSRV). We assessed the usefulness of their embeddings using four evaluation metrics, two of them relative to their acoustic properties and two of them relative to their perceptual properties via human listeners' similarity ratings. Results suggest that models conditioned on both sound-type labels (drum vs imitation) and drum-type labels (kick vs snare vs closed hi-hat vs opened hi-hat) learn the most informative embeddings for DSRV. We finally looked into individual differences in vocal imitation style via the Mantel test and found salient differences among participants, highlighting the importance of user information when designing DSRV systems.
Deep Embeddings for Robust User-Based Amateur Vocal Percussion Classification
Apr 10, 2022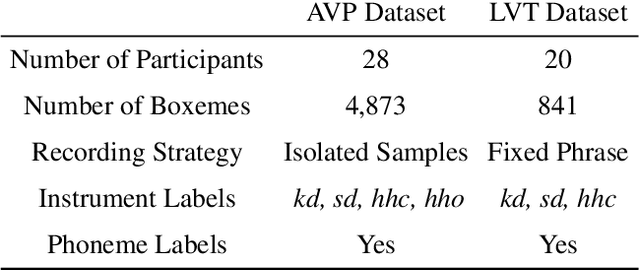


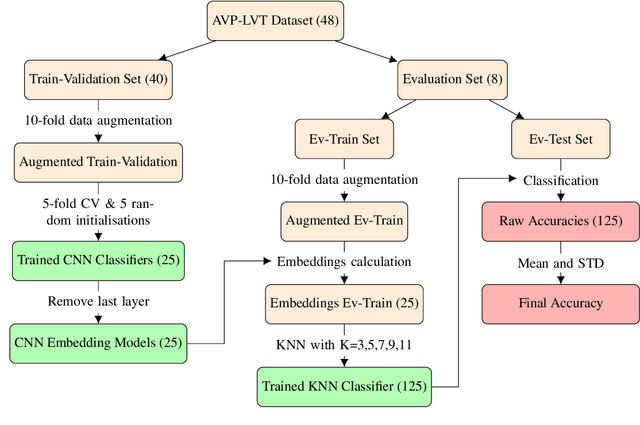
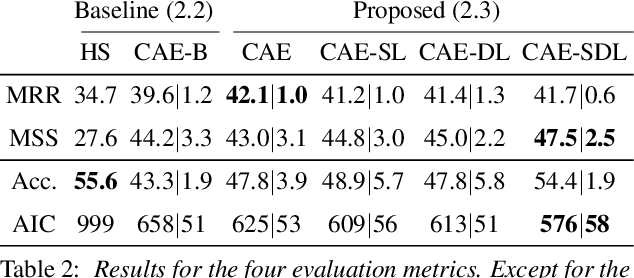
Vocal Percussion Transcription (VPT) is concerned with the automatic detection and classification of vocal percussion sound events, allowing music creators and producers to sketch drum lines on the fly. Classifier algorithms in VPT systems learn best from small user-specific datasets, which usually restrict modelling to small input feature sets to avoid data overfitting. This study explores several deep supervised learning strategies to obtain informative feature sets for amateur vocal percussion classification. We evaluated the performance of these sets on regular vocal percussion classification tasks and compared them with several baseline approaches including feature selection methods and a speech recognition engine. These proposed learning models were supervised with several label sets containing information from four different levels of abstraction: instrument-level, syllable-level, phoneme-level, and boxeme-level. Results suggest that convolutional neural networks supervised with syllable-level annotations produced the most informative embeddings for classification, which can be used as input representations to fit classifiers with. Finally, we used back-propagation-based saliency maps to investigate the importance of different spectrogram regions for feature learning.
Learning Models for Query by Vocal Percussion: A Comparative Study
Oct 18, 2021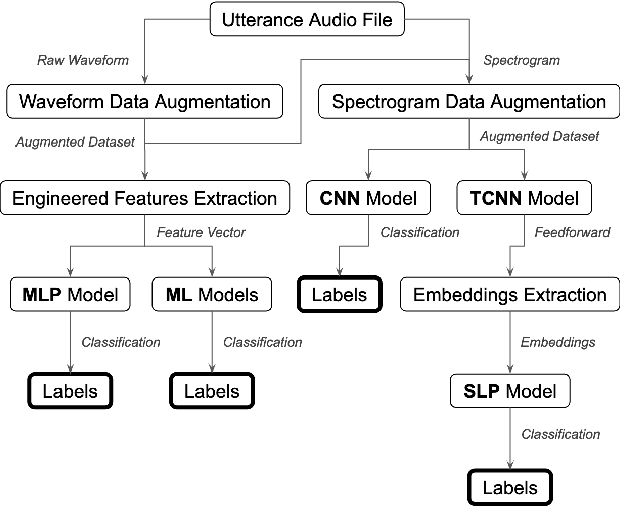

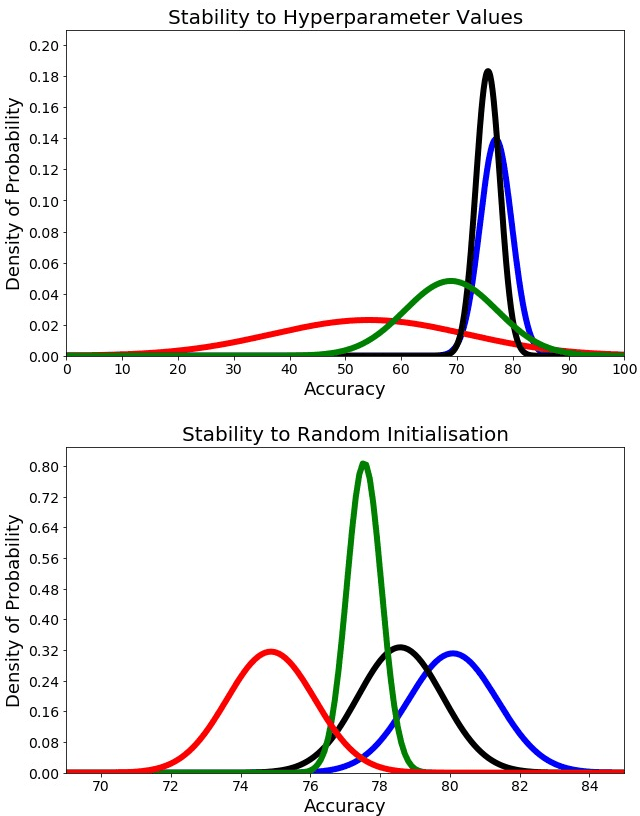
The imitation of percussive sounds via the human voice is a natural and effective tool for communicating rhythmic ideas on the fly. Thus, the automatic retrieval of drum sounds using vocal percussion can help artists prototype drum patterns in a comfortable and quick way, smoothing the creative workflow as a result. Here we explore different strategies to perform this type of query, making use of both traditional machine learning algorithms and recent deep learning techniques. The main hyperparameters from the models involved are carefully selected by feeding performance metrics to a grid search algorithm. We also look into several audio data augmentation techniques, which can potentially regularise deep learning models and improve generalisation. We compare the final performances in terms of effectiveness (classification accuracy), efficiency (computational speed), stability (performance consistency), and interpretability (decision patterns), and discuss the relevance of these results when it comes to the design of successful query-by-vocal-percussion systems.